MiniMax M3 vs Qwen 3.7 Max: A Head-to-Head Comparison
Last Updated:
2026-06-09
MiniMax M3 vs Qwen 3.7 Max: A Head-to-Head Comparison
In this article, we're going to compare MiniMax M3 and Qwen 3.7 Max — two Chinese models built by different labs, on different architectures, under different licenses — yet they're both cheaper models that promise to outperform many proprietary Western flagships. But can they punch above their weight?
To answer that question, we'll first look at published benchmarks, then run each model through a set of hard prompts on coding, math, and more.
Both models are available to test on Overchat AI, which is where the real-world prompts below were run.
If you'd prefer not to read the full comparison, here's a table summarising the key details:
Attribute
Llama
Claude
Best for
Open-weight deployment, long-context and multimodal work, natural writing
Math and reasoning-heavy text work
License
Open-weight
Proprietary, API-only
Modality
Text, image, video
Text only
Context
1M tokens
1M tokens
Released
June 1, 2026
May 20, 2026
Price (input/output per 1M)
~$0.60 / $2.40
~$2.50 / $7.50
Quick recommendations by use case:
For coding: It's close. Qwen 3.7 Max scores higher on the benchmarks, but in our own test both models reached the same optimal solution and MiniMax explained it better.
For math: Qwen 3.7 Max. It posts the strongest competition-math figures of any Chinese model, and it edged MiniMax in our own math test too.
For writing: MiniMax M3. This was the clearest gap we saw — its prose felt far more natural than Qwen's.
For multimodal or long-context tasks: MiniMax M3, the only one of the two that accepts image and video input.
For self-hosting or cost-sensitive scale: MiniMax M3, which ships open weights and the lower per-token price.
Across the three hands-on tests, we preferred using MiniMax M3 overall. It won two of the three, and its explanations were consistently clearer.
MiniMax M3 vs Qwen 3.7 Max at a Glance
Before we look at the specific benchmarks, let's first establish what these models are and compare their specifications. Here's a table containing the most important information about each model:
Spec
MiniMax M3
Qwen 3.7 Max
Developer
MiniMax (Shanghai Hixi Technology)
Alibaba (Qwen team)
Release date
June 1, 2026
May 20, 2026
License
Open-weight
Proprietary
Architecture
MiniMax Sparse Attention (MSA)
Dense reasoning model
Modality
Text, image, video
Text
Context window
1M tokens (512K guaranteed)
1M tokens
Thinking mode
Toggleable
Always on
SWE-Bench Pro
59.0% (vendor-reported)
Vendor-reported, see benchmarks
Input price (per 1M)
~$0.60
~$2.50
Output price (per 1M)
~$2.40
~$7.50
Key Differences
You've probably noticed from the table above that there are 4 areas where these models differ the most in terms of their specs:
License: M3 is open-weight, with weights published for self-hosting. Qwen 3.7 Max is closed and reachable only through Alibaba's API.
Modality: M3 accepts image and video input natively. Qwen 3.7 Max is text-only.
Architecture: M3 uses a sparse-attention design built for long-context efficiency. Qwen 3.7 Max is a reasoning model that runs its thinking process on every request.
Price: M3 is roughly four times cheaper on input tokens.
Who Each Model Is Best For
MiniMax M3 is best for users who need to self-host the model, or anyone who wants to send images or video inputs. It's also the cheaper model of the two, making it a good choice for high volume tasks where you expect to burn through a lot of tokens. In our testing it was also the stronger writer, so it's a good pick for long-form and creative work.
The Qwen 3.7 Max is best suited to text-only tasks that require the model to demonstrate significant reasoning ability: complex backend coding problems, advanced mathematical calculations and analysing large statistical databases.
What Is MiniMax M3?
MiniMax M3 is the flagship language model released by the Shanghai lab MiniMax on June 1, 2026.
It's the first open-weight model to simultaneously offer:
Frontier-level coding performance
A one-million-token context window
Ability to process images and videos natively
Architecture and Training Approach
M3 is built on a new attention mechanism that the lab calls MiniMax Sparse Attention (MSA). Most models use dense attention, which gets more expensive very quickly as the input gets longer. That cost is the main reason long context windows are hard to offer. MSA is designed to handle very long inputs while keeping that cost low.
MiniMax says this makes M3 much faster than its previous M2 model when working with very long inputs. It also helps with a specific problem in long tasks. As a conversation grows, a model normally has to re-process more and more text on every step, and MSA is built to reduce that overhead.
Key Capabilities
Let's take a look at the main features of MiniMax M3:
Coding. This is the capability MiniMax leads with. On SWE-Bench Pro — a benchmark that hands the model real bug reports from open-source projects and checks whether its fix passes the project's tests — M3 scores 59 percent. That is higher than the scores MiniMax reports for GPT-5.5 and Gemini 3.1 Pro, and just below Claude Opus 4.7, which is strong company for an open-weight model.
Multimodal input. M3 can read images and video, and it can operate a desktop computer.
Long context. It has a 1M-token context window, with a guaranteed minimum of 512K tokens. That is large enough to hold an entire codebase or a long document in a single prompt.
Toggleable thinking mode. You can turn its step-by-step reasoning on or off for each request, depending on whether the task needs it.
Pricing and Availability
Here's where things stand on getting access to M3 and what it costs:
License: open-weight. MiniMax planned to publish the model weights and a technical report on Hugging Face and GitHub within about ten days of launch, so you can run it on your own hardware.
API: already live, at around $0.60 per million input tokens at standard context length. Calls above 512K tokens cost more.
Easiest way to try it: directly onOverchat AI, with no setup.
What Is Qwen 3.7 Max?
Qwen 3.7 Max is the flagship model in Alibaba's Qwen family. Alibaba announced it at the Alibaba Cloud Summit in Hangzhou on May 20, 2026. It is a text-only model built for reasoning, coding, and long tasks.
Architecture and Training Approach
Qwen 3.7 Max is a reasoning model. It works through a problem step by step before giving an answer, rather than replying straight away. The model also marks a strategic shift for Alibaba. Earlier Qwen models were open-weight, but Qwen 3.7 Max is proprietary and API-only. It is Alibaba's first move toward a closed-frontier approach.
Key Capabilities
Let's take a look at where Qwen 3.7 Max is strongest. It stands out most on mathematics and reasoning, where it scores higher than any other Chinese model on the main benchmarks:
HMMT competition mathematics — 97.1. HMMT is one of the hardest high-school maths competitions in the United States. A score this high means the model solves nearly all of the problems, and it is the top score in Alibaba's comparison table.
GPQA Diamond — 92.4. GPQA Diamond is a set of graduate-level science questions written to be "Google-proof," so they reward reasoning rather than recall. PhD-level experts answer around 65 percent correctly, which makes 92.4 a very strong result.
Humanity's Last Exam — 41.4. This is a deliberately brutal benchmark of expert questions across many fields, where even the best models score low. A higher number is better, and Qwen leads its Chinese peers here.
Long context — 1M tokens. Its context window is up from 256K on the previous Qwen 3.6 Max, which puts it in line with other current flagship models.
Pricing and Availability
Here's how to access Qwen 3.7 Max and what it costs:
License: proprietary. There are no open weights, so you cannot self-host it.
Where to reach it: through Alibaba Cloud Model Studio and compatible API endpoints.
Price: roughly $2.50 per million input tokens and $7.50 per million output tokens, about half the price of comparable Western flagships.
Easiest way to try it: directly onOverchat AI, the same place you can test M3.
Release Timeline
MiniMax M3 Release History
Early 2026 — M2.5 and M2.7. MiniMax released several M-series models in quick succession. M2.7 was notable because the lab said the model helped develop itself, running optimization loops on its own.
Weeks before launch — architecture teasers. MiniMax began previewing its new sparse-attention design ahead of the model's release.
June 1, 2026 — M3 launch. The model went live through the MiniMax API and the MiniMax Code app, with thinking mode that can be switched on or off.
Within ~10 days of launch — open weights. MiniMax planned to publish the model weights and a full technical report on Hugging Face and GitHub.
Qwen 3.7 Max Release History
May 14, 2026 — preview on LM Arena. A preview version showed up on the public LM Arena leaderboard, with no press release. Its text Elo score reached about 1,475, near the top ten for math, coding, and software tasks.
May 18–19, 2026 — API goes live. Access opened on third-party platforms and on Alibaba Cloud Model Studio, a day before the public announcement.
May 20, 2026 — official launch. Alibaba formally announced Qwen 3.7 Max at the Alibaba Cloud Summit in Hangzhou.
A strategic shift. Unlike earlier open-weight Qwen models, Qwen 3.7 Max shipped as a closed, proprietary model — Alibaba's first move toward a closed-frontier approach.
Qwen 3.7 Max vs Qwen 3.7 Plus
Alibaba released two models under the Qwen 3.7 name within weeks of each other. They are built for different jobs:
Qwen 3.7 Max is text-only and was released on May 20, 2026. It is built for coding, reasoning, and long text tasks. This is the model used in this comparison.
Qwen 3.7 Plus is multimodal and was released on June 1, 2026. It is built on the Max model, with added vision and screen-control features for computer-use tasks.
Benchmark Performance
Here's how both models performed in the benchmarks. Just a quick note, the numbers come directly from the developers and there are some tests that don't cover both models. We'll mark the performance of a model that wasn't tested with a "~" sign.
Benchmark
What it measures
MiniMax M3
Qwen 3.7 Max
SWE-Bench Pro
Fixing real bugs in open-source codebases
59.0%
~
Coding (aggregate)
Average across head-to-head coding tests
67.0
73.6
Terminal-Bench 2.0
Running terminal commands safely and correctly
66.0%
69.7%
Agentic (aggregate)
Average across head-to-head agentic tests
71.9
69.7
HMMT
Hard high-school competition mathematics
~
97.1
PolyMATH
Multilingual competition mathematics
~
86.5
GPQA Diamond
Graduate-level, "Google-proof" science questions
~
92.4
Humanity's Last Exam
Very hard expert questions across many fields
~
41.4
In short, the published numbers say Qwen 3.7 Max is stronger on coding, math, and reasoning, while MiniMax M3 leads on agentic tasks and wins clearly on price and openness. The next section checks whether Qwen's reasoning lead shows up on real prompts.
Real-World Testing
Now we'll put both models through three tests, each covering a different skill: hard algorithmic coding, mathematical reasoning, and long-form writing.
Testing Methodology
We ran both models onOverchat AI, which offers MiniMax M3 and Qwen 3.7 Max in one place. This let us give each prompt to both models under the same conditions. Every task used the same prompt for both, with no follow-up help. Each answer below is shown as the model returned it. The prompts come from established benchmarks.
Evaluation Criteria
We judge each task against a fixed set of criteria that suits its type:
Coding: Does the code handle edge cases, run correctly, use a sensible approach, and come with a clear explanation?
Math and reasoning: Is the final answer correct, and is the working sound and complete?
Writing: Does it follow the brief, have a clear voice, hold together, and avoid padding?
Test 1: Hard Algorithmic Coding
This is "Trapping Rain Water," a classic problem that LeetCode lists as Hard.
Prompt
Given n non-negative integers representing an elevation map where the width of
each bar is 1, compute how much water it can trap after raining.
For example, given the heights [0,1,0,2,1,0,1,3,2,1,2,1], the answer is 6.
Constraints:
- n == height.length
- 1 <= n <= 20,000
- 0 <= height[i] <= 100,000
Provide a solution that runs in linear time and uses constant extra space, and
explain the idea behind your approach.
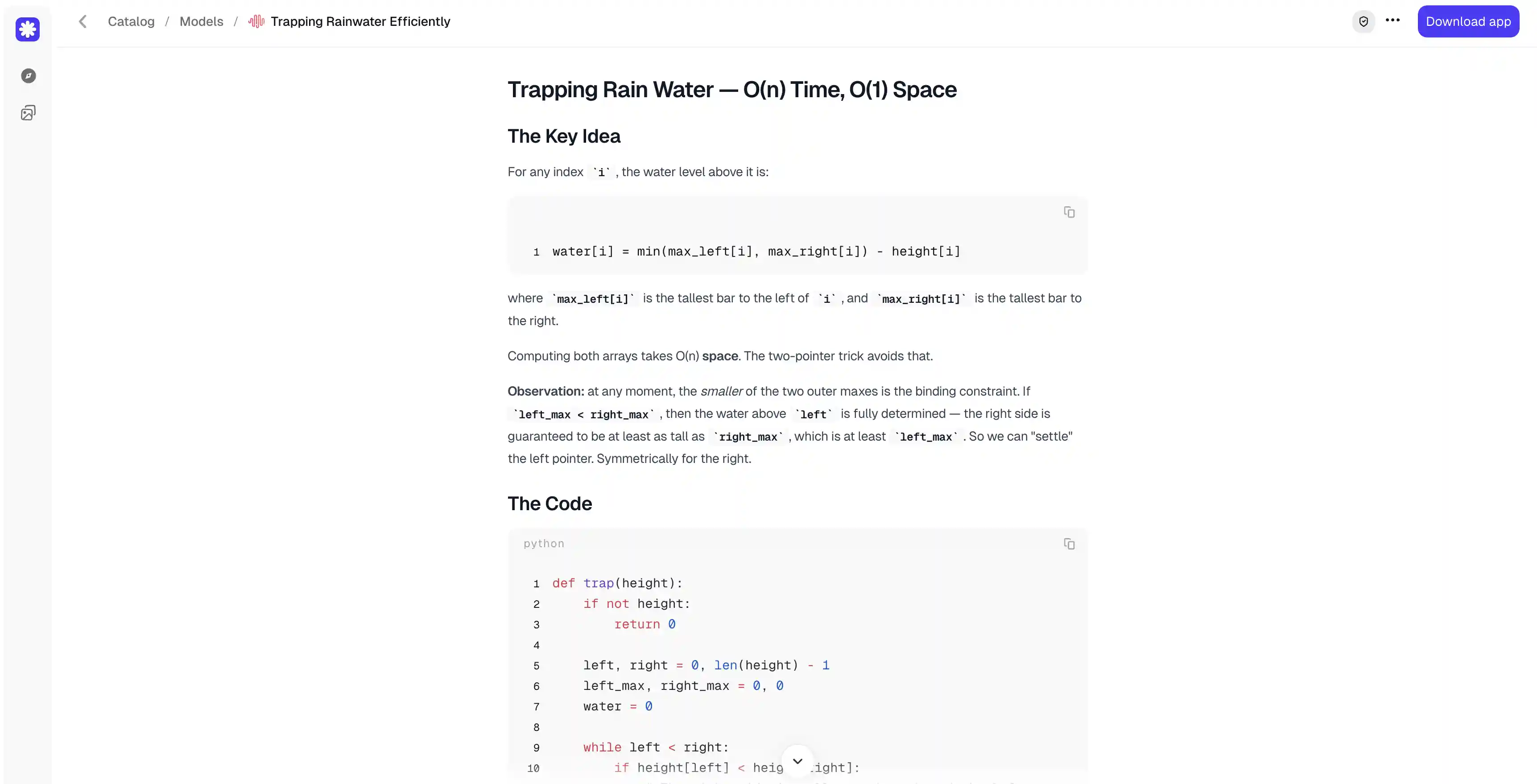
The naive approach checks every bar against the tallest bars to its left and right, which works but runs in O(n²) time. We're looking for the better solution that runs in a single linear pass: either precomputing the running maximums from each side, or using two pointers that move inward from the ends. A strong answer should use one of these, explain the idea behind it clearly, and provide runnable code that handles the edge cases, such as an empty or flat elevation map where no water is trapped.
MiniMax M3 Results
Qwen 3.7 Max Results
Winner
Both models produced the same solution: the optimal two-pointer approach that runs in linear time and constant space.
We ran both versions against the example and a range of edge cases — an empty map, a flat one, and strictly increasing and decreasing maps — and they returned the correct answer every time. The code is functionally identical, so the explanation is what decides this one.
Each model explained the core idea well, and each included a proof of why the approach is correct, which is more than the prompt asked for.
However, MiniMax added two things Qwen did not.
A step-by-step walk-through of the example, tracing the pointers and the running water count at each step, which makes the logic easy to follow.
A short table comparing all four common approaches — brute force, prefix/suffix arrays, monotonic stack, and two pointers — that shows at a glance why two pointers is the only one meeting both the time and space limits.
Qwen's answer is excellent, and its correctness proof, laid out as a numbered argument, is arguably the cleaner of the two. Even so, the walk-through and the comparison table make MiniMax's response more complete and more useful to anyone learning the problem.
Winner: MiniMax M3.
Test 2: Complex Math and Reasoning
This is a problem taken word-for-word from HMMT November 2025 (Problem 9). HMMT is one of the hardest amateur mathematics competitions in the United States. The problem has a single verifiable answer.
Prompt
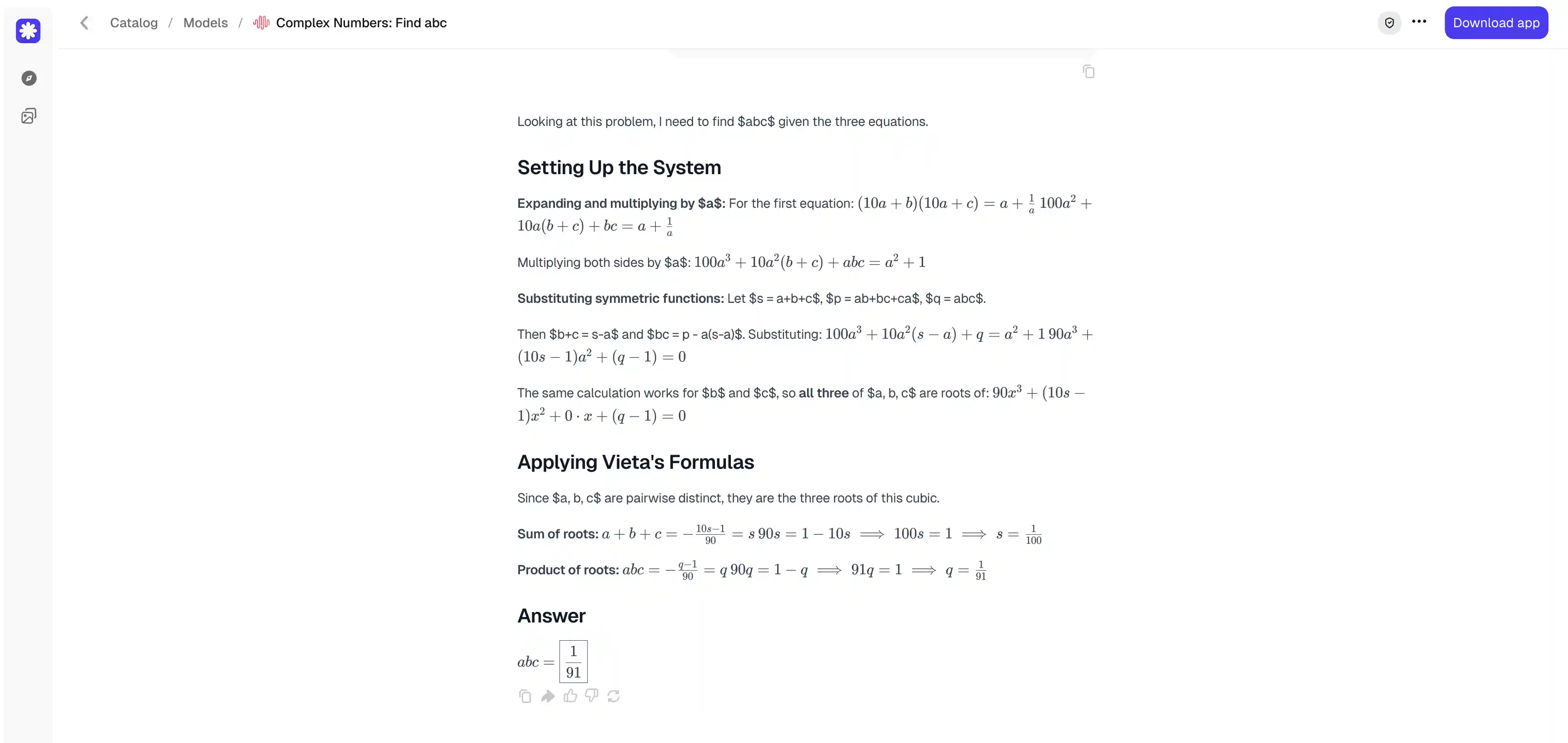
Let a, b, and c be pairwise distinct nonzero complex numbers such that
(10a + b)(10a + c) = a + 1/a,
(10b + a)(10b + c) = b + 1/b,
(10c + a)(10c + b) = c + 1/c.
Compute abc.
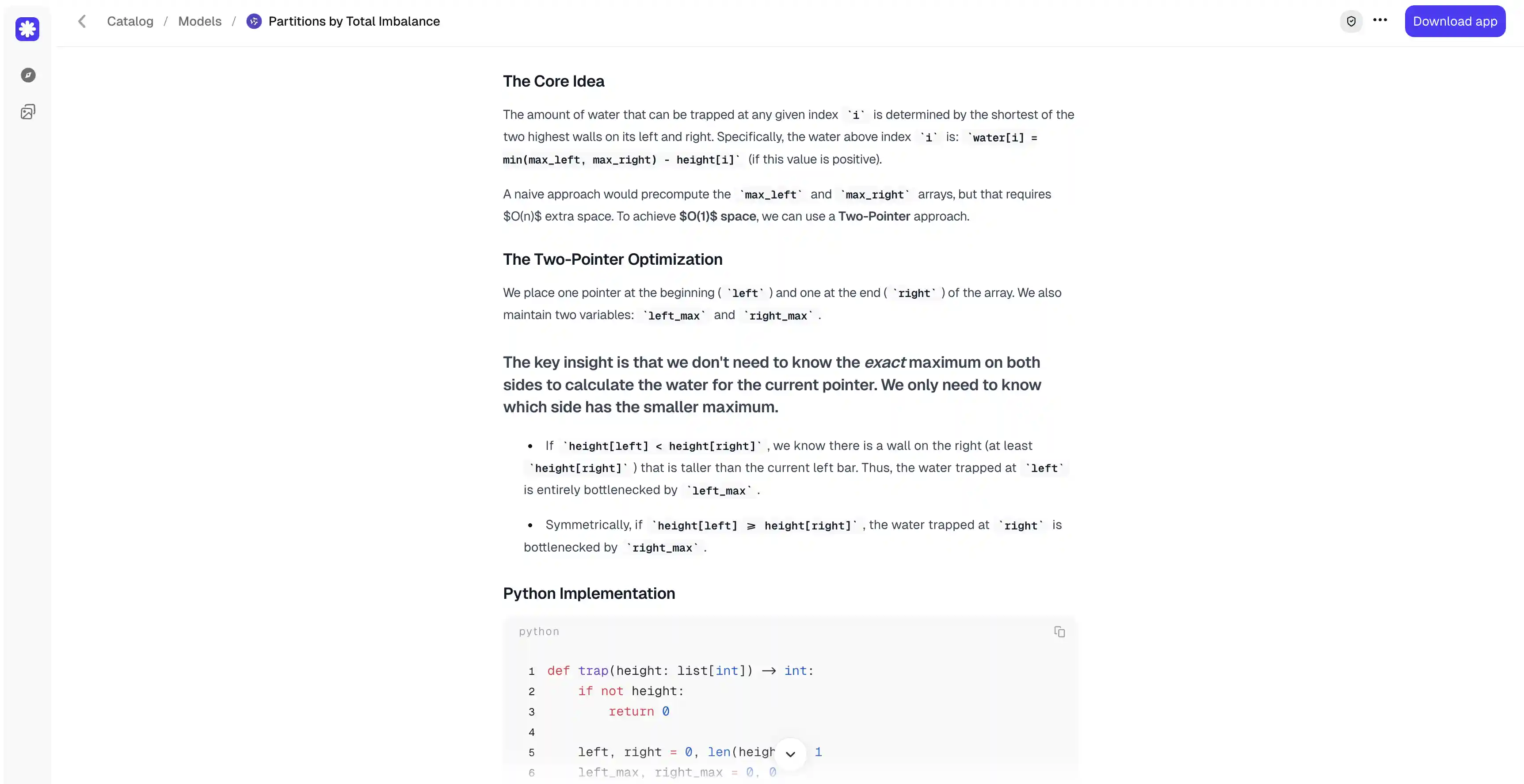
The correct answer here is 1/91. A strong response should reach that value through a clear derivation, without skipping over the hard steps, and should state the final answer plainly instead of leaving it buried in the working.
MiniMax M3 Results
Qwen 3.7 Max Results
Winner
Both models reached the correct answer of 1/91, so this test comes down to how they got there, and they took noticeably different routes.
MiniMax M3 multiplied each equation through by its variable and rewrote everything in terms of the symmetric functions — the sum, the pairwise products, and the product abc. That let it show that a, b, and c are all roots of the same cubic, and two applications of Vieta's formulas then gave the sum and the product directly. The derivation is compact and reaches the answer without a wasted step.
Qwen 3.7 Max took the equations in pairs and subtracted them from one another. The matching terms cancelled, the differences factored out, and the whole system collapsed to a single relationship: 91 = 1/abc. Qwen then kept going. It derived the same cubic M3 had used, checked that the roots match the required sum and product, and confirmed that the three numbers really are distinct and nonzero.
Both derivations are sound, and neither skips over the hard steps. The verification is what separates them. The problem specifies that a, b, and c are pairwise distinct nonzero complex numbers, and only Qwen confirmed that such numbers actually exist and satisfy the conditions. M3 stopped the moment it had the answer. That extra check makes Qwen's solution the more complete and trustworthy of the two.
Winner: Qwen 3.7 Max.
Test 3: Long-Form Writing
This test looks at open-ended writing under firm constraints. The constraints let us judge the result on how well it follows the brief and whether it has a real voice, rather than on a vague impression.
Prompt
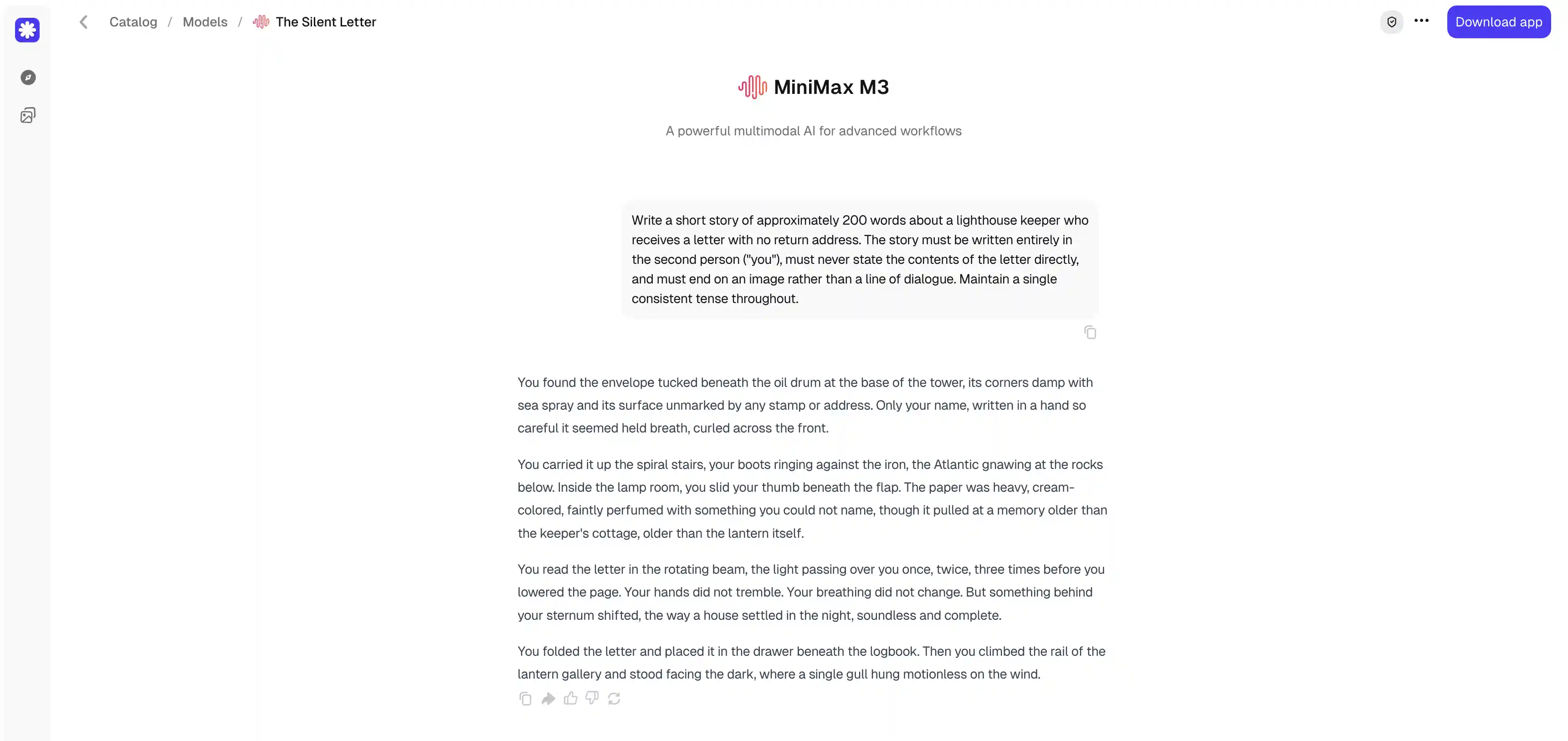
Write a short story of approximately 600 words about a lighthouse keeper who
receives a letter with no return address. The story must be written entirely in
the second person ("you"), must never state the contents of the letter directly,
and must end on an image rather than a line of dialogue. Maintain a single
consistent tense throughout.
The story has to hit all four constraints: second person throughout, the contents of the letter never stated, an ending on an image rather than dialogue, and one consistent tense. On top of that, we're looking for a real voice rather than generic prose, a structure that holds together from start to finish, and enough restraint to avoid padding and clichés.
MiniMax M3 Results
Qwen 3.7 Max Results
Winner
It’s interesting to see that both stories overlap a fair amount: the same beats of carrying the envelope up the stairs, reading it in the beam, folding it away, and ending on the view.
However, in our opinion, MiniMax uses sensory detail in a way that feels far less forced, reading like something you might find in a real book. Lines such as "the Atlantic gnawing at the rocks below," "you slid your thumb beneath the flap," and "it pulled at a memory older than the keeper's cottage, older than the lantern itself" carry some weight. This is united AI writing, mind you, but it doesn’t immediately register as slop, especially if you’re not trying to harshly judge it.
Meanwhile, Qwen piles its details on more mechanically, as if working too hard to show rather than tell. The images it settles on are plainer for that effort, and the strain shows through.
However, in fairness, MiniMax did slip into AI-slop territory with "Your hands did not tremble. Your breathing did not change. But something behind your sternum shifted." Still, we have to give this one to MiniMax M3.
Winner: MiniMax M3.
Strengths and Weaknesses
Where MiniMax M3 Performs Best
M3 is the only one of the two that can read images and video. It is also open-weight, so you can run it on your own hardware. Its sparse-attention design makes long-context work cheaper, and it leads Qwen on agentic and tool-use benchmarks.
Our own testing added two more strengths to that list. M3 was the clearly better writer, producing prose that felt natural where Qwen's felt forced.
It also explained its answers better across the board: on both the coding and math tests, even where the two models reached the same result, M3's write-up was easier to follow. For high-volume or multimodal work, and for anyone who values a clear, readable response, these strengths often matter more than a point or two on text-reasoning benchmarks.
Where Qwen 3.7 Max Performs Best
Qwen 3.7 Max leads on the published figures for coding, mathematics, and graduate-level reasoning.
Its biggest lead is in competition math, and that held up in our own testing: it won the math test, reaching the right answer and being the only one of the two to verify its work.
Which Model Should You Choose?
Let’s quickie summarize and talk about which model you should pick based on the task before you.
Best Model for Coding
This one is close. Qwen 3.7 Max scores higher on the published coding benchmarks, so on paper it's better.
But in our own coding test the two were hard to separate: both reached the same optimal solution, and MiniMax actually came out ahead on the strength of a clearer explanation. We’d say — go with MiniMax.
Best Model for Math
Qwen 3.7 Max is the better choice for math. It posts the highest competition-math scores of any Chinese model, and math is the area where it pulls furthest ahead of M3.
Best Model for Writing
MiniMax M3. This was the biggest gap we saw in any of the three tests. M3's prose felt like something from a real book. For long-form or creative writing, M3 is the clear pick.
Best Model for Business Use
It depends on what matters most to your business.
If you need data control, self-hosting, or image and video input, MiniMax M3.
If you mainly do text-heavy analysis and want the strongest reasoning, Qwen 3.7 Max.
Bottom Line
According to the published benchmarks, Qwen 3.7 Max is the stronger model for coding, mathematics, and reasoning. However, in our own testing, MiniMax M3 came out ahead in the three hands-on tests, winning the coding and writing tasks. This was mainly a matter of subjective preference — it felt better to work with this model. However, when working with AI, all you do is read its replies, so the ability to deliver clear explanations and communicate clearly should not be underestimated. For this reason alone, and given that both models are genuinely very strong, we would recommend using MiniMax M3 over Qwen 3.7 Max for most people — at least if you have to choose just one.
Which, you might not need to at all, since onOverchat AI you can try both side by side in one place, and decide which one you like more, or simply keep using them both at the same time.
FAQ
Is MiniMax M3 better than Qwen 3.7 Max?
Neither is better across the board. Qwen 3.7 Max leads on published coding, math, and reasoning benchmarks. MiniMax M3 leads on agentic tasks, multimodality, openness, and price. In our own hands-on tests, M3 came out ahead overall, winning the coding and writing tasks while Qwen took math, and we preferred using it. The right choice still depends on whether your priority is reasoning benchmarks or things like cost, flexibility, and writing quality.
Which model is better for coding: MiniMax M3 or Qwen 3.7 Max?
It's close. Qwen 3.7 Max scores higher across the coding benchmarks the two were compared on, so on paper it's the stronger coder. In our own test, though, both reached the same optimal solution and MiniMax edged it on a clearer explanation. M3 also leads on agentic coding tasks specifically, where the model works step by step through a larger job.
Which model performs better on math and reasoning tasks?
Qwen 3.7 Max. It posts the strongest competition-math figures of any Chinese model, including a reported 97.1 on HMMT. It also leads on graduate-level reasoning benchmarks such as GPQA Diamond.
How does MiniMax M3 compare to Qwen 3.7 Plus?
They target different jobs. M3 is an open-weight, multimodal model for general reasoning and long-context work. Qwen 3.7 Plus is a multimodal agent model built for screen perception and computer-use tasks. For GUI and agentic vision work, Plus is the closer comparison. For general reasoning, M3 stands on its own.
Is Qwen 3.7 Max worth upgrading from Qwen 3.7 Plus?
They are not really an upgrade path for one another. Max is text-only and reasoning-focused, while Plus adds vision and GUI control. Choose Max for text reasoning and coding, and choose Plus for tasks that require the model to see and operate an interface.
Which model has the larger context window?
They match. Both MiniMax M3 and Qwen 3.7 Max ship a 1M-token context window. M3 guarantees a minimum of 512K tokens at full fidelity.
Which model is faster for real-world tasks?
This depends on the task and the thinking mode. M3's sparse-attention architecture is built for speed at long contexts, and it lets you turn thinking off for simple tasks. Qwen 3.7 Max runs its reasoning process on every request, which can add latency on tasks that would not need it.
Which model produces better long-form writing?
MiniMax M3, by a clear margin in our testing. Given the same creative-writing brief, its prose read naturally, while Qwen 3.7 Max piled on sensory detail in a way that felt forced. This was the widest quality gap we saw across the three tests.
Can MiniMax M3 and Qwen 3.7 Max use tools and agents?
Yes. Both are built for agentic and tool-use work, and both labs market long-horizon autonomous capabilities. On published head-to-head benchmarks, M3 holds a slight edge on agentic and tool-use measures.
Which model is more cost-effective?
MiniMax M3. It costs roughly $0.60 per million input tokens against Qwen 3.7 Max's ~$2.50, which makes it about four times cheaper on input. Its open weights also allow self-hosting, which can cut costs further at scale.
What are the biggest differences between MiniMax M3 and Qwen 3.7 Max?
There are four. M3 is open-weight while Qwen is closed. M3 is multimodal while Qwen is text-only. M3 uses sparse attention while Qwen is a dense reasoning model. And M3 is substantially cheaper. On capability, Qwen leads on text reasoning while M3 leads on agentic tasks.
Is MiniMax M3 open source?
M3 is open-weight. MiniMax publishes the model weights for download and self-hosting, with a technical report released alongside. Open-weight means the trained model itself is available, which is the part that matters for self-hosting.
Is Qwen 3.7 Max open source?
No. Qwen 3.7 Max is proprietary and API-only. This is a notable break from earlier Qwen models, which were released under permissive open-weight licenses.
What is the best alternative to MiniMax M3 and Qwen 3.7 Max?
It depends on the need. DeepSeek's V4 family is another strong open-weight option. Western flagships such as Claude Opus, GPT-5.5, and Gemini 3.1 Pro offer frontier capability at a higher cost. Qwen 3.7 Plus is the option for multimodal agent work. Several of these can be compared directly on Overchat AI.