Is MiniMax M3 a good alternative to Opus 4.8? Let’s break it down.
Claude Opus 4.8 is one of the most expensive AI models (costing $5 per million input tokens and $25 per million output) and given that the previous generation Opus 4.7 received shaky reviews, many people are looking for alternatives — and MiniMax shipped M3 can just be that for many people, as it costs a lot less and provides a similar level of performance.
In this article we’re going to break down the new model, where it can replace Opus 4.8, and where it still falls short in real-world usage.
When was MiniMax M3 released? MiniMax M3 came out on June 1, 2026.
Why is this release significant? MiniMax M3 is the first open-weights model that performs on the level of frontier models, features a 1M token context window, and is natively multimodal.
How much does MiniMax M3 cost? API pricing is $0.60 per million input tokens and $2.40 per million output — roughly 5–10% of Opus 4.8's cost.
How does MiniMax M3 perform in the real world? It’s very close to Opus 4.8 and other proprietary flagships.
Where does MiniMax M3 come short? The model tends to over-think simple problems, burning tokens.
What Is MiniMax M3?
Before we get into the comparison let’s first talk about what this new model is.
MiniMax M3 is a flagship text generation AI model developed by Shanghai Hixi Technology, a Chinese AI company. They’re calling this the most advanced open weight model ever released, and there’s substance to this claim:
M3 performs on the level of closed source flagship models (we share benchmarks later in the text)
The model supports multimodal input, peaning it understands text, image, and video.
It features a 1M token context window, same as Opus 4.8, for example.
It comes with a new attention architecture called MiniMax Sparse Attention (MSA), which reduces token burn and costs.
This combination of features is unique among open-weight models. For example, Qwen 3.7 Max isn’t multimodal — if you want to chat with images, you would need to downgrade to Qwen 3.7 Plus.
Why MiniMax M3 Is a Real Alternative to Opus 4.8
Along those lines, there are several reasons to consider this model over Antrophi’s flagship, and we’re breaking them down below.
1. MiniMax M3 is 10-20x Cheaper than Opus 4.8
First of all, the price difference is monumental.
Opus 4.8 costs $5 per million input tokens and $25 per million output
M3 costs $0.60 input and $2.40 output at standard rates
For context, a task that would cost $5 on Opus 4.8 would cost roughly $0.30 and $0.60 on M3.
As flagged by VentureBeat: MiniMax-M3 eclipses GPT-5.5 and Gemini 3.1 Pro on key benchmark performance for just 5–10% of the cost.
2. 1M context window
Some models that support 1 million tokens of context, become slow and expensive when the full context window is utilized.
But the team behind M3 found a clever way to solve this problem. Instead of processing the entire context equally, it quickly identifies the parts that are most relevant to the current task and focuses its attention there.
This reduces the amount of computation required without forcing the model to compress or discard large portions of the context.
The company reports a 9.7x improvement in prompt processing speed, a 15.6x improvement in generation speed, and roughly 20x lower compute costs at a 1-million-token context window.
3. The coding performance is elite
SWE-Bench Pro is a benchmark that measures how many real-world GitHub issues the model can fix as a percentage. It probably translates most closely to how the model performs in the real world. Here’s how some of the flagship models compare:
Opus 4.8 can solve 69.2%
M3 can solve 59.0% of the problems
GPT-5.5 can solve 58.6%
Gemini 3.1 Pro can solve 54.2%
First user reviews reinforce those numbers. For example, a Sydney-based AI engineer Thomas Wiegold ran his standard battery of coding tests and reported that the results were "right up there with the closed frontier models" and the code audit was "remarkably close" to GPT-5.5, his usual favorite for audits.
MiniMax M3 Vs Opus 4.8: The Benchmarks
Let’s pitch the two flagship models against each other and see how they perform in the most popular AI benchmarks. Here’s a table comparison:
Benchmark
MiniMax M3
Claude Opus 4.8
SWE-Bench Verified
80.5%
88.6%
SWE-Bench Pro
59.0%
69.2%
Terminal-Bench 2.1
66.0%
74.6%
MCP Atlas
74.2%
82.2
What we can see from the table above is that Opus 4.8 is clearly a more advanced coding model, but you should bear in mind that it’s also more expensive by a factor of ten. And, on balance, there are other areas where M3 likely beats Opus 4.8.
We say "likely" because Anthropic hasn't released SVG-Bench results for Opus 4.8. What we do know is that M3 scores higher than Opus 4.7 on that benchmark, and Anthropic has described Opus 4.8 as a relatively modest upgrade over 4.7 for this specific workflow.
Note: MiniMax ran and reported all of the M3 benchmark results itself. Many of the tests also used Claude Code as the agent framework. Independent testing is still needed, so don't treat these numbers as definitive.
Minimax M3 vs Opus 4.8: Real-World Performance
We asked both models to build a polished landing page for a wedding photographer's website. We ran them both in Overchat AI.
This is a useful test because it measures more than just coding ability. The models need to create an attractive design, write clean code, avoid bugs, and stay consistent across a fairly long response.
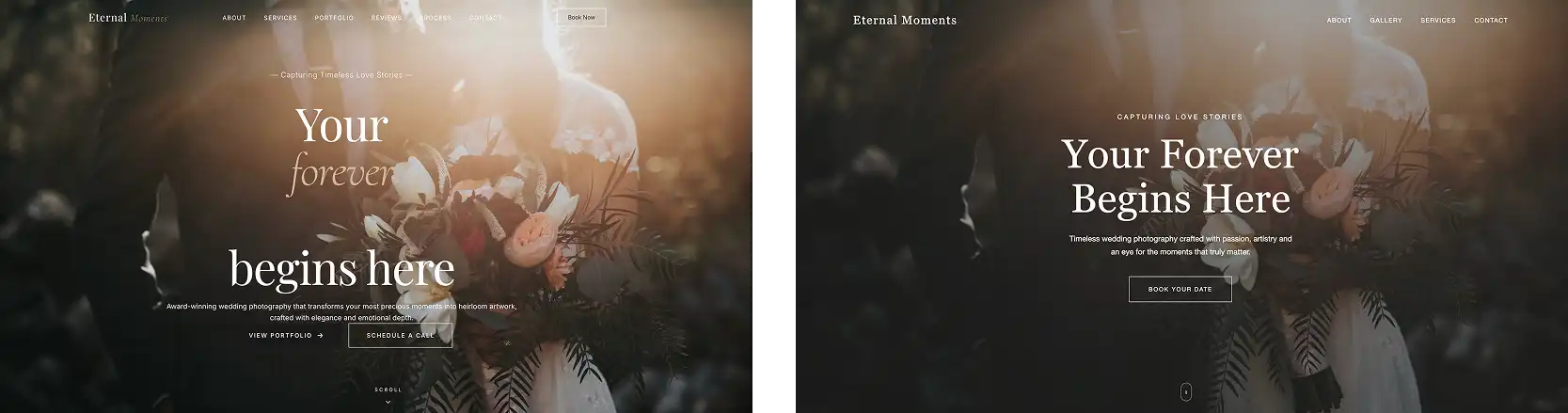
Let's take a look at the results. MiniMax M3 left, Opus 4.8 right:
It's interesting that both models chose a very similar look, even down to choosing the same image for the hero splash screen.
But this isn’t a knock on MiniMax, given that Opus models are known for their attractive UI. However, looking at the very first screen it's clear that MiniMax made a mistake, as the vertical spacings between the elements is uneven and random.
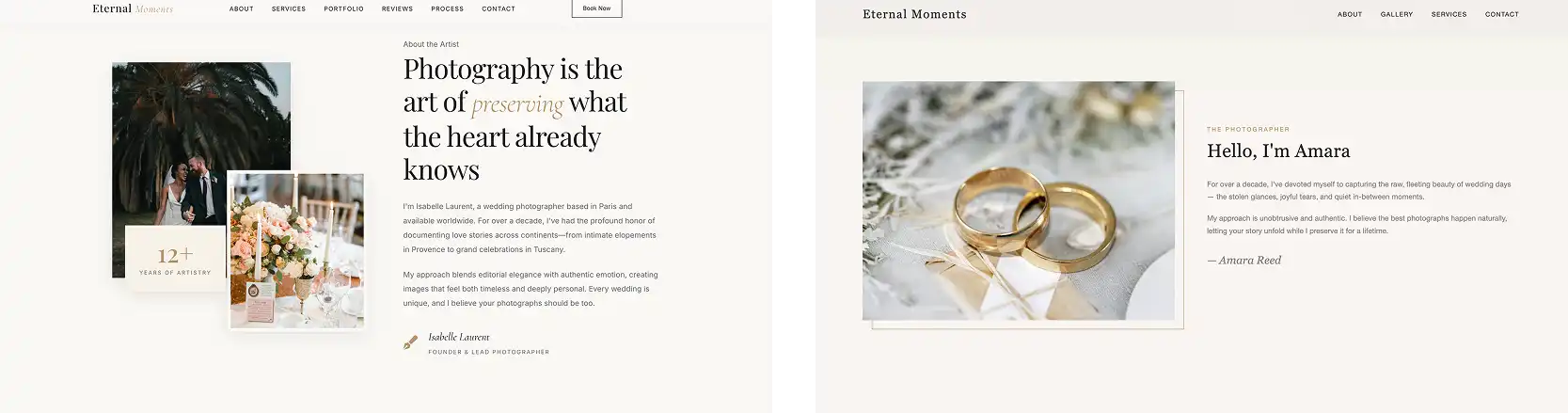
Looking at another section (below), MiniMax actually chose to execute a much more complicated and rich layout than Opus 4.8, stacking multiple images, adding a much bigger and impactful heading and playing with proportions in a more deliberate way:
MiniMax M3 left, Opus 4.8 right:
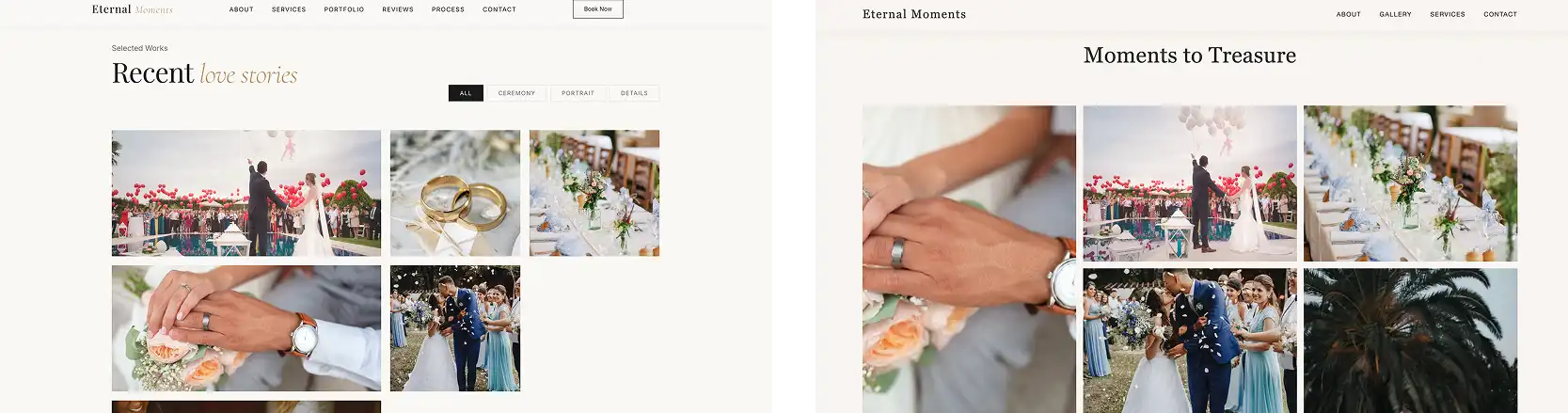
The MiniMax M3 also has an entire gallery with interactive tabs, whereas the Opus only includes status card images (below). It seems that the model is ambitious and approaches the task with enthusiasm, so to say.
MiniMax M3 left, Opus 4.8 right:
MiniMax also highlights M3's ability to work on long-running tasks without human intervention.
In one test, the model reportedly reproduced an ICLR 2025 Outstanding Paper over the course of 12 hours. During that time, it made 18 code commits and generated 23 experimental figures on its own.
In another test, M3 was asked to optimize an FP8 kernel for Nvidia Hopper GPUs. After 24 hours of work, 147 experimental runs, and roughly 2,000 tool calls, it increased hardware utilization from 7.6% to 71.3%.
MiniMax M3 Limitations
That being said, there are a few areas in which Opus 4.8 still beats the Chinese flagship. Most notably:
Opus 4.8 is still the stronger coding model for complex tasks. Coding a landing page is one thing, but what if you need to solve a hard algorithm challenge?M3 scores about 10 points lower on SWE-Bench Pro. If you regularly work on large refactors, complex codebases, or difficult engineering tasks, Opus 4.8 is probably going to solve more issues with a lower failure rate.
The model over-thinks. This is most evident when you simply chat — you’ll notice that M3 tends to talk to itself before answering simple questions. This not only makes the reply time longer, but it’s also expensive as internal reasoning burns tokens.
Weak on abstract reasoning. While M3 performs well on coding and agent tasks, it has scored poorly on ARC-AGI-2, a benchmark designed to test reasoning on completely new types of problems. If your work depends heavily on abstract problem-solving rather than coding or tool use, choose Opus 4.8.
When to Choose MiniMax M3 vs Opus 4.8
The short version:
Choose MiniMax M3 for lower costs, long-context work, multimodal inputs, and flexibility.
Choose Claude Opus 4.8 for the strongest coding performance and the most reliable outputs.
Reach for MiniMax M3 when:
You're running large volumes of requests and want to keep API costs low. It also stands out for its 1 million token context window, which makes it well suited for large codebases, long documents, and research workflows that require a lot of context.
It's also the more flexible option. M3 can work with image and video inputs, and its open-weight release should make it attractive for teams that want to self-host or fine-tune models in the future.
Finally, if your workflow involves autonomous web browsing, M3 currently has the stronger published results.
Reach for Claude Opus 4.8 when:
You want a stronger model for difficult software engineering tasks. If you regularly work on large refactors, complex bug fixes, or architecture-level decisions, it still has a clear edge.
You care about reliability. Anthropic reports major improvements in alignment and a significant reduction in coding mistakes compared to Opus 4.7.
If your main goal is getting the best possible results and cost is a secondary concern, Opus 4.8 is the safer choice.
What is the MiniMax M3 Pricing?
API pricing (pay-as-you-go):
Input (standard): $0.60 per million tokens
Input (launch promo, first week): $0.30 per million tokens
Output (standard): $2.40 per million tokens
Output (launch promo, first week): $1.20 per million tokens
MiniMax also offers token-bundle subscriptions through their consumer surface:
Plus ($20/month): ~1.7 billion tokens, 3–4 concurrent agents
Max ($50/month): ~5.1 billion tokens, 4–5 concurrent agents, plus 3 Hailuo 2.3 video clips per day
Ultra ($120/month): ~9.8 billion tokens, 6–7 concurrent agents, plus 5 video clips per day
For comparison, the equivalent token volume on Opus 4.8 would cost 10–20x more, depending on input/output ratio.
By the way, you don't have to use the API to access M3. Overchat AI bundles it together with Claude Opus 4.8, GPT-5.5, Gemini 3.5 Flash, Qwen 3.7, and other major models under a single subscription, at just $14.99/month.
How to Access MiniMax M3
There are several options, and which one is right for you depends on how you plan to use the model:
Overchat AI — you can chat with M3 alongside Opus 4.8, GPT-5.5, Gemini 3.5 Flash, and other frontier models under a single subscription. Open MiniMax M3 here.
MiniMax API — get direct platform access for production integrations.
OpenRouter — OpenAI-compatible API, the easiest path for teams already using OpenRouter for other models.
MiniMax Code — MiniMax's own agentic coding interface, also going open-source.
Hugging Face / GitHub — for self-hosting.
FAQ
Is MiniMax M3 better than Claude Opus 4.8?
It depends on what you care about.
For coding quality, Opus 4.8 is still the stronger model. It leads M3 on major software engineering benchmarks and is generally the safer choice for difficult coding tasks.
M3's advantage is cost. It is dramatically cheaper to run while still delivering performance that is competitive with the top models. For many teams, that makes it the better value.
How much does MiniMax M3 cost?
MiniMax M3 costs:
$0.40 per million input tokens
$2.20 per million output tokens
That makes it one of the cheapest frontier-class models currently available.
Does MiniMax M3 support images and video?
Yes. M3 can work with text, images, and video in a single model. This makes it easier to build multimodal applications without combining multiple models.
Does MiniMax M3 have a 1 million token context window?
Yes. M3 supports up to 1 million tokens of context. More importantly, MiniMax claims the model was designed to remain fast and efficient at long context lengths, rather than simply supporting them on paper.
How does MiniMax M3 compare to Kimi K2.6?
The two models are very close overall. Both perform well on coding and agent tasks, and both are priced aggressively. M3's main advantages are multimodal support and its long-context architecture, while Kimi K2.6 remains one of the strongest open-weight coding models available.
Is MiniMax M3 good for coding?
Yes. Coding is one of M3's strongest areas. It performs well on software engineering benchmarks and supports long-running agent workflows. However, if you want the absolute best coding model regardless of cost, Opus 4.8 still has an edge.
What is MiniMax M3 best at?
M3 is strongest at:
Coding and software engineering
Long-context tasks
Agent workflows
Web browsing and research
Multimodal applications using text, images, and video
Its biggest selling point is the combination of strong performance and very low cost.
Should I use MiniMax M3 or Claude Opus 4.8?
Choose M3 if you want lower costs, multimodal support, or a very large context window.
Choose Opus 4.8 if you want the strongest coding performance and the most reliable outputs, and cost is less important.
Bottom Line
So which is better, Opus 4.8 or MiniMax M3? On paper, Opus 4.8 is the better model, but what makes M3 interesting is how close it gets while costing a fraction of the price. It also supports images and video, and offers a 1 million token context window. For many users, the small performance trade-off is likely worth it. At the very least you should try it on your real-life tasks to see if you’re fine with a slightly higher error rate.