O GPT-5.2 é o principal modelo de raciocínio da OpenAI, lançado no início de dezembro de 2025, e traz grandes avanços em inteligência geral, compreensão de contextos longos, chamada de ferramentas com agentes e visão computacional.
Ele chega em três configurações: GPT-5.2 Instant (tarefas do dia a dia), GPT-5.2 Thinking (tarefas complexas, programação, análise de documentos) e GPT-5.2 Pro (nível empresarial, para os problemas mais difíceis e fluxos de trabalho com agentes).
No GDPval — um benchmark que cobre 44 profissões — o GPT-5.2 Thinking empata ou supera os melhores profissionais do setor em 70,9% das comparações, quase o dobro da taxa de vitória de 38,8% do GPT-5.1. Segundo os relatos, usuários do ChatGPT Enterprise economizam, em média, de 40 a 60 minutos por dia.
Programação: o GPT-5.2 marcou 55,6% no SWE-Bench Pro e 80,0% no SWE-bench Verified, com ganhos notáveis em desenvolvimento front-end e interfaces complexas.
As alucinações caíram 30% em relação ao GPT-5.1 — a taxa de erro em consultas reais do ChatGPT baixou de 8,8% para 6,2%.
É o primeiro modelo da OpenAI a atingir precisão de quase 100% na variante de 4 agulhas do MRCR com 256 mil tokens, o que o torna confiável para documentos e planilhas muito longos.
Apesar dos ganhos em raciocínio, a OpenAI afirma que o GPT-5.2 Thinking entrega resultados profissionais 11 vezes mais rápido do que especialistas humanos e por menos de 1% do custo.
vs Gemini 3 Pro: o GPT-5.2 vence no SWE-bench Verified (80,0% contra 76,2%), no raciocínio matemático e na análise de documentos; o Gemini ainda lidera na compreensão multimodal (vídeo, imagens).
vs Claude Opus 4.5: o Opus 4.5 leva uma leve vantagem sobre o GPT-5.2 no SWE-bench Verified (80,9% contra 80,0%) — diferença mínima — mas o GPT-5.2 domina no raciocínio abstrato (ARC-AGI-2: 52,9% contra 37,6%).
vs DeepSeek V3.2: o GPT-5.2 vence em matemática, programação e raciocínio científico, mas o DeepSeek V3.2-Speciale fica apenas 0,2% atrás no HMMT de fevereiro de 2025 — e custa 4 vezes menos por token (US$ 0,42 contra US$ 1,75 por milhão de tokens de entrada), além de ser totalmente de código aberto.
O lançamento apressado foi a resposta de "código vermelho" de Sam Altman ao Gemini 3 e ao Claude Opus 4.5, que superaram o GPT-5.1 — Marc Benioff, da Salesforce, trocou publicamente o ChatGPT pelo Gemini 3 depois de apenas duas horas.
Olhando para frente: o Project Garlic da OpenAI (que pode ser lançado como GPT-5.5 ou GPT-6 no início de 2026) usa uma nova arquitetura que cria um modelo menor capaz de reter o conhecimento de um sistema maior, com o objetivo de reduzir custos computacionais e acelerar os tempos de resposta.
Trade-off de desenvolvimento: assistentes digitais e ferramentas iniciais de publicidade foram despriorizados para acelerar o lançamento do GPT-5.2.
O que é o GPT-5.2?
O GPT-5.2 é um modelo de raciocínio de nível principal lançado em dezembro de 2025 pela OpenAI.
Segundo a OpenAI, o GPT-5.2 traz avanços significativos em:
Inteligência geral
Compreensão de contextos longos
Chamada de ferramentas com agentes
Visão computacional.
A empresa o projetou especificamente para o trabalho profissional do conhecimento, e os primeiros testes mostram que ele economiza, em média, de 40 a 60 minutos por dia para os usuários do ChatGPT Enterprise.
O modelo chega em três configurações:
GPT-5.2 Instant para tarefas do dia a dia
GPT-5.2 Thinking para tarefas complexas, programação e análise de documentos
GPT-5.2 Pro para os problemas mais difíceis e fluxos de trabalho com agentes — uma IA de nível empresarial
Para quem estava cético em relação ao GPT-5.2, aqui vai a boa notícia. O GPT-5.2 é, sem dúvida, um grande salto em relação ao GPT-5.1, já que supera a versão anterior em quase todos os benchmarks — mesmo com o lançamento apressado, a OpenAI entregou algo impressionante.
Os maiores ganhos estão no trabalho profissional do conhecimento. No GDPval, uma avaliação que mede tarefas bem especificadas em 44 profissões, o GPT-5.2 Thinking supera ou empata com os melhores profissionais do setor em 70,9% das comparações — quase o dobro da taxa de vitória de 38,8% do GPT-5.1.
Em outras palavras, esse modelo consegue executar uma tarefa tão bem quanto um especialista sênior, quando não melhor.
Veja como o GPT-5.2 se compara ao GPT-5.1 nos benchmarks:
Benchmark
GPT-5.2 Thinking
GPT-5.1 Thinking
Melhoria
GDPval (vitórias ou empates)
70,9%
38,8%
+82%
SWE-Bench Pro
55,6%
50,8%
+9%
SWE-bench Verified
80,0%
76,3%
+5%
GPQA Diamond
92,4%
88,1%
+5%
AIME 2025
100,0%
94,0%
+6%
FrontierMath (Tier 1–3)
40,3%
31,0%
+30%
ARC-AGI-1
86,2%
72,8%
+18%
CharXiv Reasoning
88,7%
80,3%
+10%
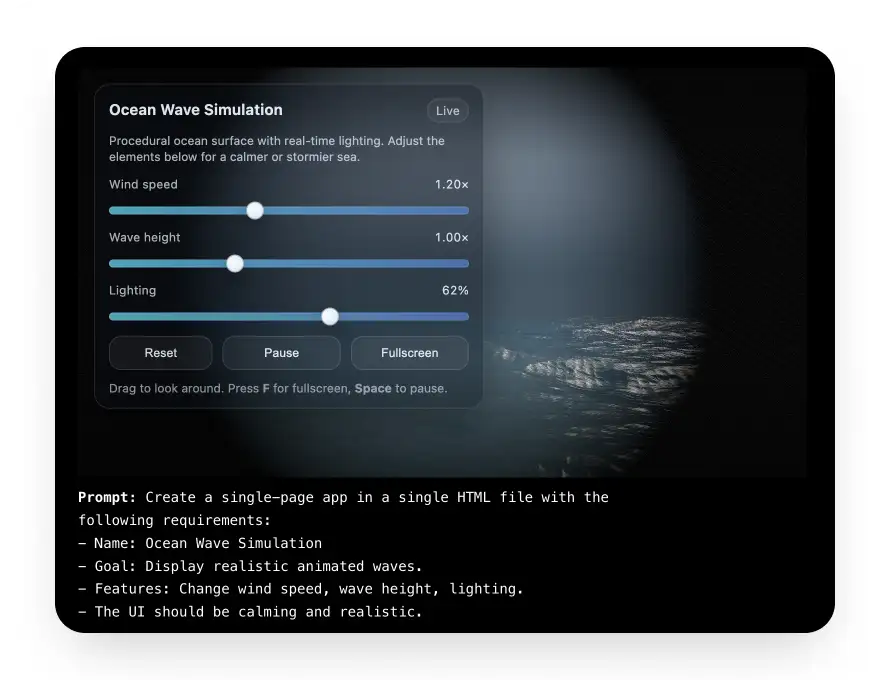
O SWE-Bench Pro mede o desempenho em tarefas de programação desafiadoras. O GPT-5.2 alcançou uma pontuação de 55,6% nesse benchmark notoriamente difícil, que testa quatro linguagens de programação. Embora 5% possa parecer pouco, é uma melhoria significativa, especialmente em desenvolvimento front-end e interfaces complexas.
Por exemplo, veja este aplicativo de simulação de ondas que o GPT-5.2 criou com um único prompt:
Outra grande melhoria é a redução substancial das alucinações: o GPT-5.2 gera 30% menos respostas inventadas do que o GPT-5.1. Quando testado em um conjunto de consultas reais do ChatGPT, a proporção de respostas com erros caiu de 8,8% para 6,2%, tornando o modelo uma ferramenta mais confiável para pesquisa, escrita e análise.
Quanto à compreensão de contextos longos, o GPT-5.2 é o primeiro modelo da OpenAI a atingir precisão de quase 100% na variante de 4 agulhas do MRCR com 256 mil tokens. Isso significa que você pode fornecer ao modelo documentos, planilhas ou arquivos muito grandes, e ele vai reter todas essas informações e responder com precisão.
Normalmente, percebemos que modelos mais inteligentes e precisos são bem mais lentos, o que é um trade-off típico entre velocidade e qualidade. No entanto, segundo as métricas internas da OpenAI, o GPT-5.2 Thinking produz resultados para tarefas profissionais 11 vezes mais rápido do que especialistas humanos, custando menos de 1% do valor.
GPT-5.2 vs outros modelos de IA
Vamos comparar o GPT-5.2 com os principais modelos do Google, da Anthropic e da DeepSeek.
GPT-5.2 vs Gemini 3.0 Pro
O GPT-5.2 e o Gemini 3 Pro são os dois modelos de IA mais poderosos disponíveis. Veja como eles se comparam:
Benchmark
GPT-5.2 Thinking
Gemini 3 Pro
Vencedor
AIME 2025 (sem ferramentas)
100,0%
95,0%
GPT-5.2
AIME 2025 (com ferramentas)
100,0%
100,0%
Empate
GPQA Diamond
92,4%
91,9%
GPT-5.2
HMMT Feb 2025
99,4%
97,5%
GPT-5.2
SWE-bench Verified
80,0%
76,2%
GPT-5.2
Humanity's Last Exam (sem ferramentas)
-
37,5%
Gemini 3 Pro
ARC-AGI-2
52,9%
31,1%
GPT-5.2
O GPT-5.2 na verdade vence no SWE-bench Verified (80,0% contra 76,2%). Essa diferença percentual é significativa e vai resultar em uma experiência de desenvolvimento bem melhor, com menos erros e código de maior qualidade desde o início.
Em outras áreas, porém, o Gemini 3 Pro ainda lidera. Por exemplo, a compreensão multimodal é um de seus pontos fortes e, apesar dos avanços da OpenAI nessa área, o Gemini ainda é melhor para entender o conteúdo de vídeos e imagens.
Na prática, no entanto, você vai perceber que os dois modelos são extremamente confiáveis para o trabalho profissional.
A escolha entre eles depende do tipo de tarefa com que você costuma trabalhar:
Raciocínio matemático, análise de documentos, engenharia de software → GPT-5.2
Tarefas multimodais, processamento de vídeo, compreensão visual → Gemini 3 Pro
GPT-5.2 vs Claude Opus 4.5
Lançado pela Anthropic em novembro de 2025, o Claude Opus 4.5 foi um dos modelos que superaram o GPT-5.1, desencadeando a resposta de código vermelho da OpenAI.
No momento do lançamento, o Claude Opus 4.5 era o melhor modelo do mundo para programação, agentes e uso de computador. Ele tem pontuações incríveis em benchmarks, e muitos desenvolvedores elogiam sua capacidade de criar front-ends complexos a partir de prompts de texto simples. Então, como ele se compara ao GPT-5.2?
Benchmark
GPT-5.2 Thinking
Claude Opus 4.5
Vencedor
SWE-bench Verified
80,0%
80,9%
Claude Opus 4.5
ARC-AGI-2
52,9%
37,6%
GPT-5.2
No papel, ao menos, o Claude Opus 4.5 ainda supera o GPT-5.2 quando o assunto é resolver tarefas do mundo real, com uma pontuação de 80,9% no SWE-bench Verified contra 80,0%. No entanto, a diferença é mínima.
Os dois modelos representam o estado da arte da engenharia de software com IA e serão um excelente parceiro de programação com IA.
Já quando o assunto é raciocínio abstrato, medido pelo ARC-AGI-2, o GPT-5.2 é muito superior ao Claude, com pontuações de 52,9% e 37,6%, respectivamente. Isso sugere uma capacidade maior de resolver problemas novos e abstratos.
GPT-5.2 vs DeepSeek V3.2
O DeepSeek V3.2 é um modelo que difere bastante daqueles criados pelas empresas privadas de IA ocidentais, já que a equipe por trás dele foca em eficiência, desenvolvendo um modelo extremamente poderoso que custa 10 vezes menos para rodar em comparação com o Claude ou o Gemini. Mas será que ele consegue vencer o GPT-5.2?
Benchmark
GPT-5.2 Thinking
DeepSeek V3.2 Speciale
Vencedor
AIME 2025
100,0%
96,0%
GPT-5.2
HMMT Feb 2025
99,4%
99,2%
GPT-5.2
GPQA Diamond
92,4%
85,7%
GPT-5.2
O GPT-5.2 supera o DeepSeek em matemática, programação e raciocínio científico. Dito isso, o DeepSeek V3.2-Speciale não fica muito atrás, em especial no benchmark de matemática HMMT de fevereiro de 2025, em que a diferença é de apenas 0,2%.
Também é importante lembrar que o DeepSeek V3.2-Speciale custa apenas 42 centavos por milhão de tokens de API, o que o torna cerca de quatro vezes mais barato que o GPT-5.2, que custa US$ 1,75 por milhão de tokens de entrada. Além disso, ele é totalmente de código aberto, enquanto o GPT-5.2 permanece fechado.
Por que o GPT-5.2 saiu tão rápido depois do GPT-5.1?
Isso é uma resposta à pressão do Gemini 3 Pro. Sam Altman, CEO da OpenAI, declarou um código vermelho interno, exigindo que as equipes acelerassem o desenvolvimento depois que o modelo Gemini 3, do Google, superou o ChatGPT em quase todos os benchmarks.
Isso porque, quando o Gemini 3 foi lançado em novembro de 2025, ele teve desempenho melhor que o GPT-5.1 em testes de raciocínio, programação e inteligência geral. Por isso, o GPT-5.2 foi projetado especificamente para eliminar essas fraquezas.
De fato, o Gemini 3, do Google, entregou o que a empresa chamou de uma nova era de inteligência, tornando-se o melhor modelo do mundo para raciocínio, programação e processamento multimodal no momento do lançamento. O CEO da OpenAI chegou a elogiar o lançamento, e líderes do setor como Marc Benioff, da Salesforce, anunciaram publicamente que estavam abandonando o ChatGPT depois de apenas duas horas com o Gemini 3.
O Claude Opus 4.5, da Anthropic, também supera o GPT-5.1 em vários benchmarks, sobretudo em programação. Tudo isso levou Sam Altman a antecipar o lançamento da próxima versão.
O objetivo é fechar a diferença de desempenho que surgiu quando o Gemini 3 e o Claude Opus 4.5 saíram na frente.
Segundo o The Verge, o GPT-5.2 foi ajustado como um modelo de raciocínio, e os testes internos da OpenAI mostram que ele supera o Gemini 3 em benchmarks de raciocínio, embora os números oficiais ainda não estejam disponíveis.
O modelo está tecnicamente pronto para o lançamento. A OpenAI agora está definindo o momento exato, e o dia 9 de dezembro surge como a data-alvo. No entanto, os testes finais podem forçar um adiamento caso encontrem bugs críticos antes do lançamento.
O que a OpenAI está preparando a seguir? O Project Garlic
A equipe usou ajuste fino e melhorias direcionadas para tornar o GPT-5.2 superior ao Gemini 3, mas, em termos de visão de longo prazo, a OpenAI está trabalhando em um projeto com o codinome "Garlic", que terá uma arquitetura de modelo totalmente nova.
Há rumores de que o Garlic pode ser lançado como GPT-5.5 ou GPT-6 no início de 2026.
O Garlic pretende criar um modelo menor que mantém a base de conhecimento de um sistema muito maior. Essa abordagem reduziria drasticamente os custos computacionais ao mesmo tempo em que melhoraria os tempos de resposta. Os primeiros benchmarks sugerem um desempenho forte em tarefas de programação, indicando que a estratégia futura da OpenAI se apoia em ganhos de eficiência, e não em escala bruta.
A abordagem dupla faz sentido. O GPT-5.2 estabiliza a posição da OpenAI no curto prazo, enquanto o Garlic posiciona a empresa para uma liderança sustentada ao longo de 2026 e além.
As prioridades de desenvolvimento mudaram
Para acelerar o GPT-5.2, a OpenAI desacelerou temporariamente outros projetos. O trabalho com assistentes digitais e ferramentas iniciais de publicidade foi despriorizado, à medida que as equipes se concentram em garantir que o próximo lançamento represente um avanço realmente significativo.
Conclusão
A OpenAI lançou o GPT-5.2 apenas algumas semanas depois de lançar o GPT-5.1 porque o Google e a Anthropic lançaram modelos melhores em programação e na resolução de problemas difíceis.
O objetivo da OpenAI é criar o melhor modelo do mundo. Ela acredita que o GPT-5.2 é superior ao Gemini 3 Pro, e os relatos sugerem que ele tem desempenho melhor que outros modelos ao lidar com tarefas complexas. Se isso for verdade, significa que o melhor modelo do mundo pode estar prestes a ser lançado.
Dito isso, novembro de 2025 viu o lançamento de tantos modelos de ponta — Google Gemini e Anthropic Claude lançaram seus melhores modelos, e o recente lançamento do DeepSeek V3.2 mostrou que modelos de código aberto já conseguem competir com sistemas proprietários, e até superá-los, custando 10 vezes menos para rodar. Será que a OpenAI tem o que é preciso para se tornar a melhor desenvolvedora de modelos de IA?
Vamos atualizar este artigo com benchmarks e dados de desempenho do mundo real assim que o GPT-5.2 for lançado oficialmente.
Perguntas frequentes (FAQ)
Quando o GPT-5.2 será lançado?
O GPT-5.2 foi lançado no início de dezembro de 2025. A OpenAI antecipou o lançamento em relação ao cronograma original, previsto para o fim de dezembro, em resposta à pressão competitiva do Gemini 3, do Google.
O que é o GPT-5.2?
O GPT-5.2 é uma atualização intermediária da linha de modelos GPT, lançada apenas algumas semanas depois do GPT-5.1. Isso é uma resposta ao fato de que o Gemini 3 Pro e o Claude 4.5 Opus tiveram desempenho melhor que o GPT-5.1 em benchmarks de programação e raciocínio.
Qual é melhor: GPT-5.2 ou Gemini 3?
O GPT-5.2 e o Gemini 3 Pro são atualmente os dois modelos de IA mais poderosos disponíveis. Eles têm desempenho semelhante na maioria dos benchmarks, com o GPT-5.2 alcançando melhores resultados em algumas áreas e o Gemini 3 Pro em outras.
O que é o Project Garlic da OpenAI?
O Project Garlic é um modelo de IA de próxima geração com arquitetura totalmente nova, que pode ser lançado como GPT-5.5 ou GPT-6 no início de 2026. O projeto cria um modelo menor que usa o conhecimento de um sistema maior. Isso significa que os custos computacionais são reduzidos, os tempos de resposta ficam mais rápidos e o desempenho em programação é aprimorado.