ChatGPT Killer? I reviewed Claude Sonnet 4 & Opus 4 AI Models
Last Updated:
2026-06-09
ChatGPT Killer? I reviewed Claude Sonnet 4 & Opus 4 AI Models
Anthropic released Claude Sonnet 4 and Opus 4. If you've been using GPT and Gemini and ignoring Claude, I think it’s time to give it a try.
I was eager to test these models' performance, and I haven't enjoyed testing new AI models as much in a while.
Here’s the TL;DR? Sonnet 4 is a workhorse upgrade that costs the same as before, while Opus 4 is their bet on "what if we made an AI that could finish an entire project."
The standout number here is Opus 4's 72.5% on SWE-bench Verified. For context, GPT-4.1 hits about 54.6% on the same test.
Both models keep the 200K context window from their predecessors. And this is one area where Claude is still lacking compared to the competition. Gemini offers 1 million tokens, and so does GPT-4.1. In practice, during my testing I haven't found many scenarios where 200K isn't enough. However, if you’re working with very large texts or codebases, you might run into limitations.
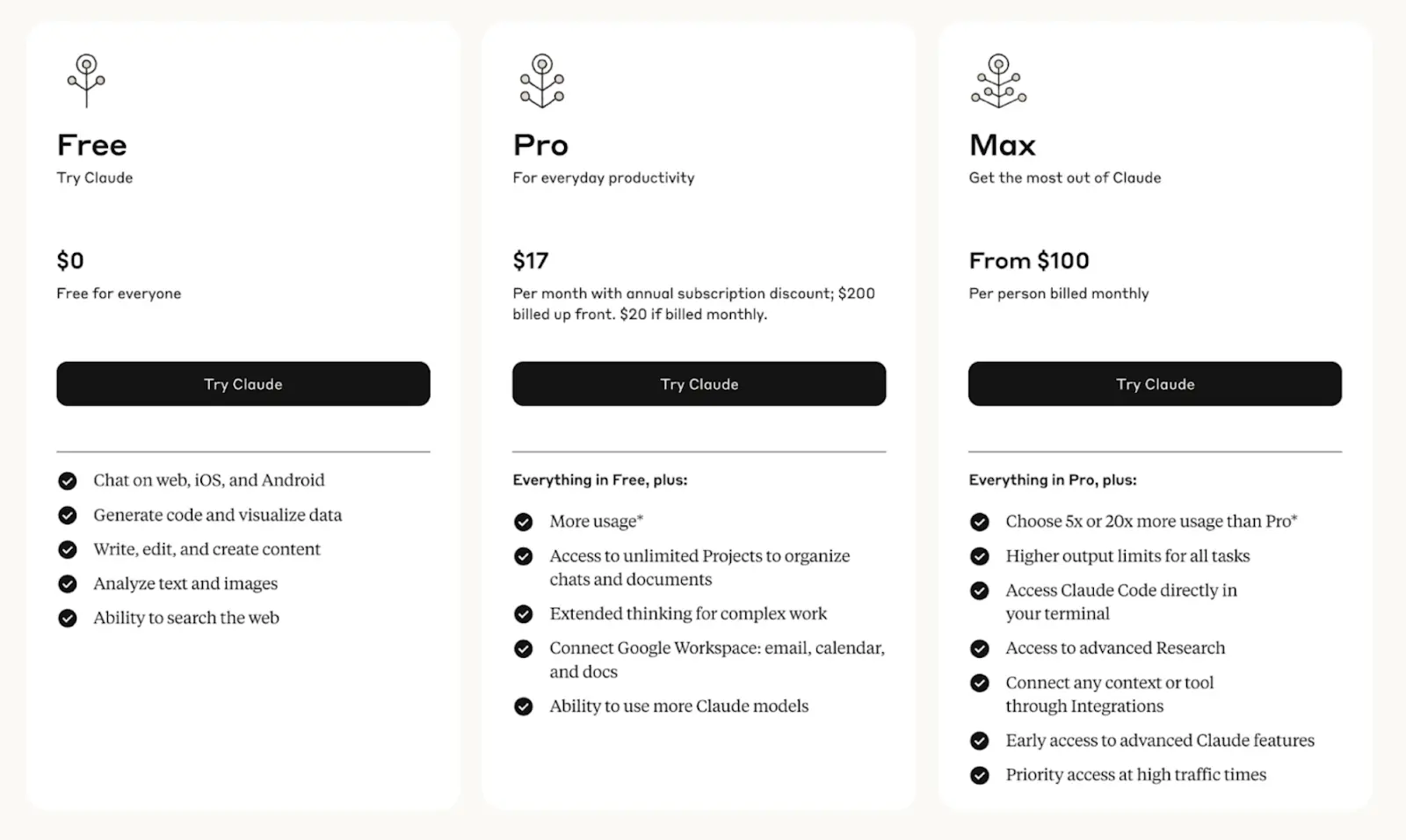
Claude 4 Pricing
As far as API pricing goes,. Sonnet 4 stays at the same price point as 3.7. Opus 4 at $15/$75 per million tokens is expensive. Still cheaper than GPT-4's input pricing though, which sits at $30 per million.
In terms of free/paid usage on Claude platform itself, Sonnet 4 is available on free and premium tiers, while Opus 4 is paywalled behind the Pro tier.
The cost is as follows:
The monthly price of $17 for the Pro plan is quoted for annual billing and comes to a total upfront payment of $200. When billed annually, the price is $20 per month.
Max is an interesting alternative to ChatGPT's Pro plan. Yes, AI naming is confusing at this point. ChatGPT's cheaper tier is called Plus. Max costs $100, while ChatGPT costs $200. This feature is geared primarily towards developers and users who need larger outputs.
For example, if you use Sonnet to write an article, Max might give you four chapters, while Pro would only give you two. The same logic applies to coding, if you need it to write a complex component or a very large class.
Claude 4 Benchmarks
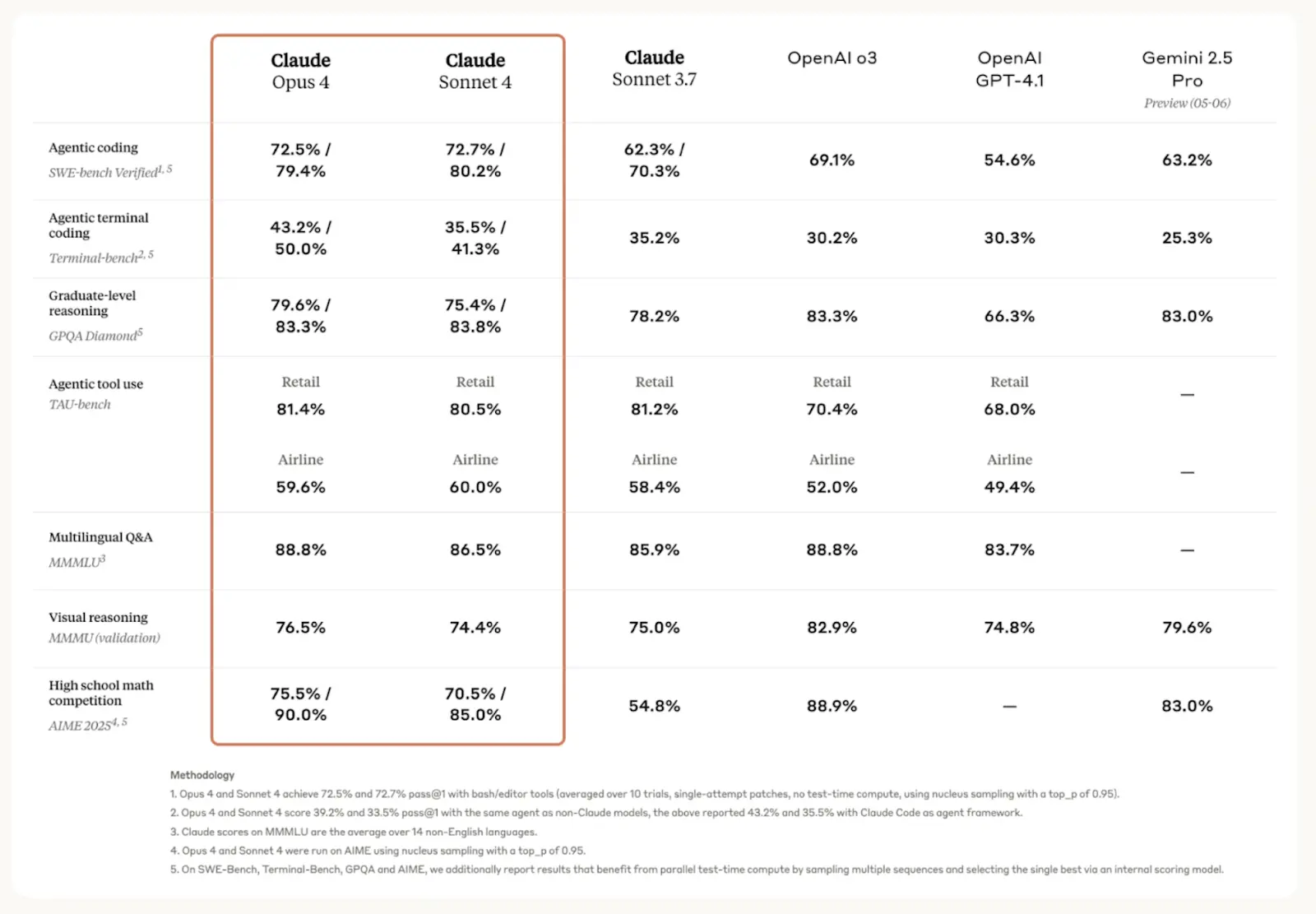
Before diving into my hands-on testing, let's take a look at the benchmarks. Because 72.7% on SWE-bench is an impressive number, but what does that translate to in real work?
If you’re wondering what to take away from these numbers besides comparing models to each other, here’s a simple breakdown:
SWE-bench Verified tests whether an AI can solve GitHub issues from popular open-source projects. Opus 4 fixed roughly 3 out of 4 real-world coding problems. GPT-4.1 barely fixed over half.
Terminal-bench measures whether the AI can iteratively write code until it works. 43.2% might sound low, but this is a brutally hard benchmark.
TAU-bench (Tool-use Agent) simulates real business workflows. Opus 4 clocked 81.4%, which means it could probably handle most customer service scenarios. But disregard this benchmark unless you’re planning to integrate Sonnet or Opus into an app.
MMLU (Massive Multitask Language Understanding) covers 57 subjects from STEM to humanities at college level. Both Claude 4 models score high 80s here, on par with GPT-4, and this is ahead of most students.
AIME tests advanced high school math competition problems. Opus 4 could probably get into MIT.
My Testing Methodology
I tested both models through Claude.ai's chat interface over the past week, focusing on real-world tasks.
My testing criteria:
Prompt-response quality: How well do they understand what I'm actually asking for?
Reasoning and problem-solving: How well can they work through multistep problems?
Multistep instruction handling: Give it a complex task with several parts. Does it remember all of them?
Real-time usability: How fast does it respond?
General-purpose chatbot interaction
Testing how these models handle general conversations.
Claude Sonnet 4
I started with a conversation about planning a technical conference. Asked Sonnet 4 to help outline the event, suggest speakers based on topics, and create a budget breakdown.
The first thing I noticed is that Sonnet immediately created an artifact — that’ useful if I want to easily export the result, or edit it:
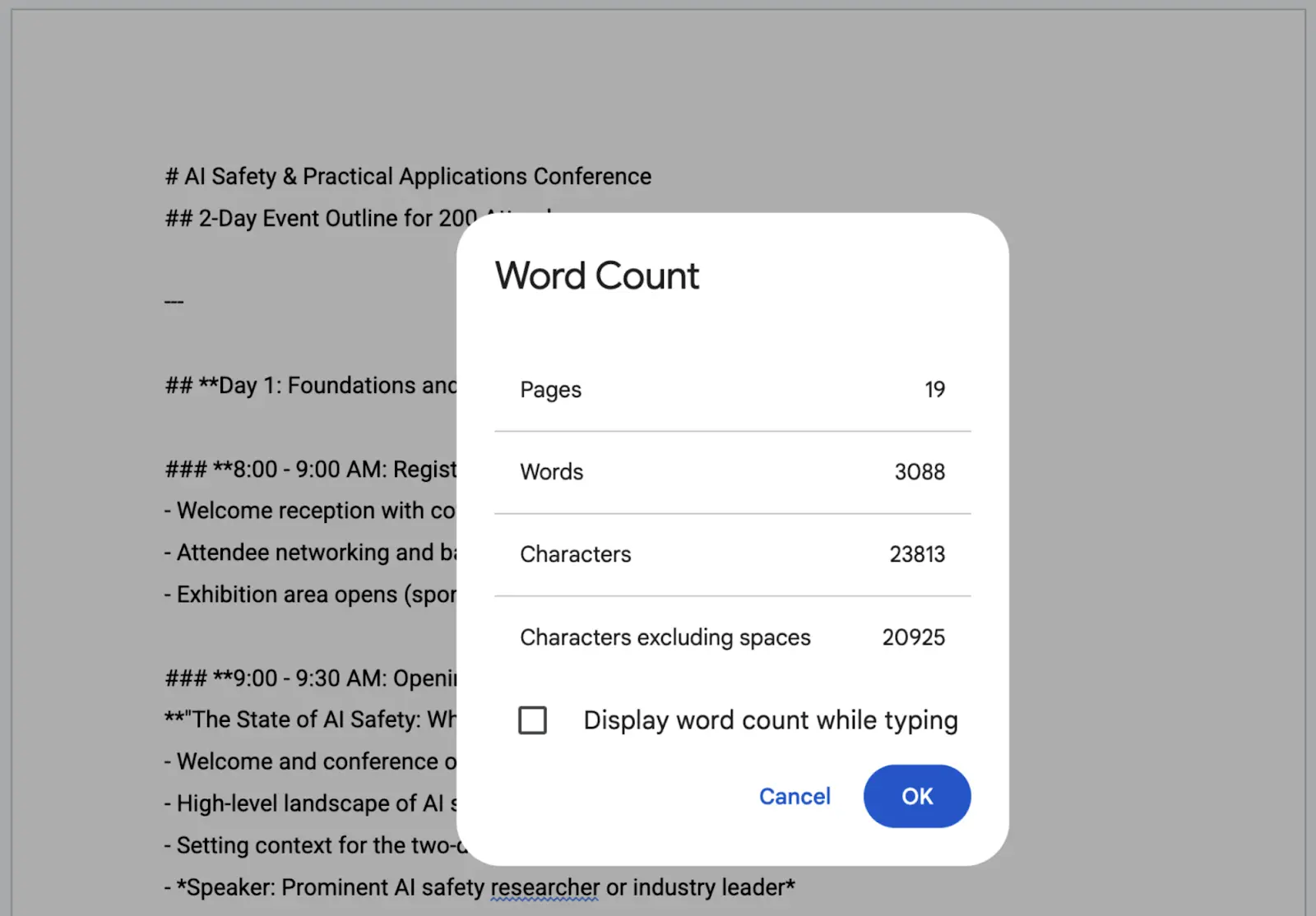
The model easily maintained context across 8–10 turns. In fact, the artifact totaled 3088 words by the time we were done — that’s one massive document.
One interesting bit: when I asked it to fit the plan into a $50k budget, it suggested different options:
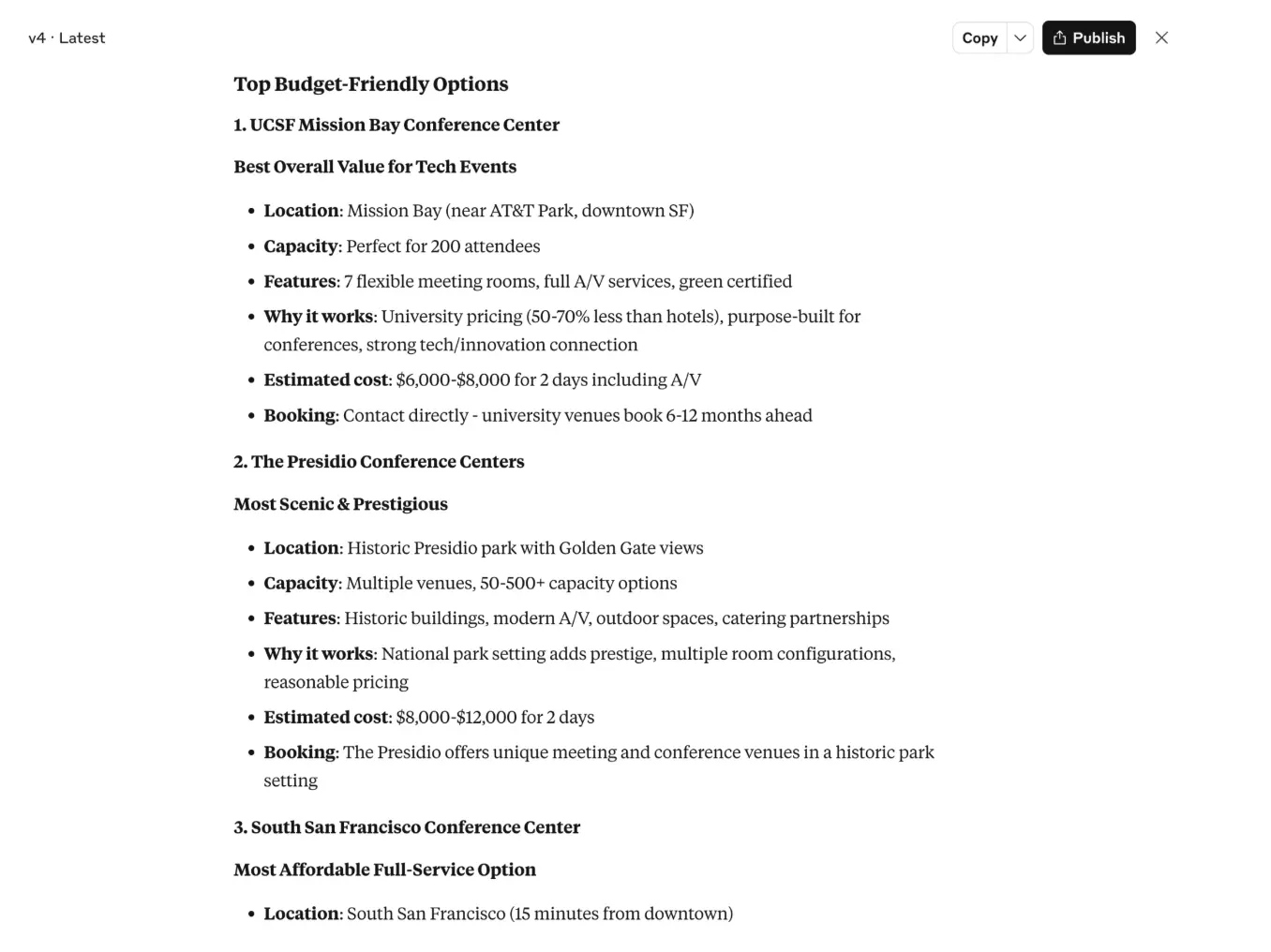
And when I asked to find suitable venues in San Francisco, Claude searched online and provided a list that took my budget into account:
Claude Opus 4
Same conference planning scenario with Opus 4.
The first thing I noticed — it didn’t create an artifact, choosing to reply in chat instead. The answers themselves — a lot shorter. But is this a bad thing? Not really, as the replies were informative:
When I mentioned the budget constraint, Opus didn't just run me through the budget breakup, it suggested cost-saving strategies as well:
And when I asked it to suggest venues, it made a tiered list, which would help me pick the most likely venues for my own research and for reaching out:
Findings
The difference is subtle but very noticeable. On the surface, both models did the same thing (even their suggestions were similar.)
However, Sonnet 4 went overboard with the amount of information — who has time to read through 25,000 symbols? Opus 4 was less verbose and managed to deliver the same amount of value white using fewer words — about 2000, including my messages.
Coding
For this challenge, I tested everyday debugging and code improvement tasks.
Claude Sonnet 4
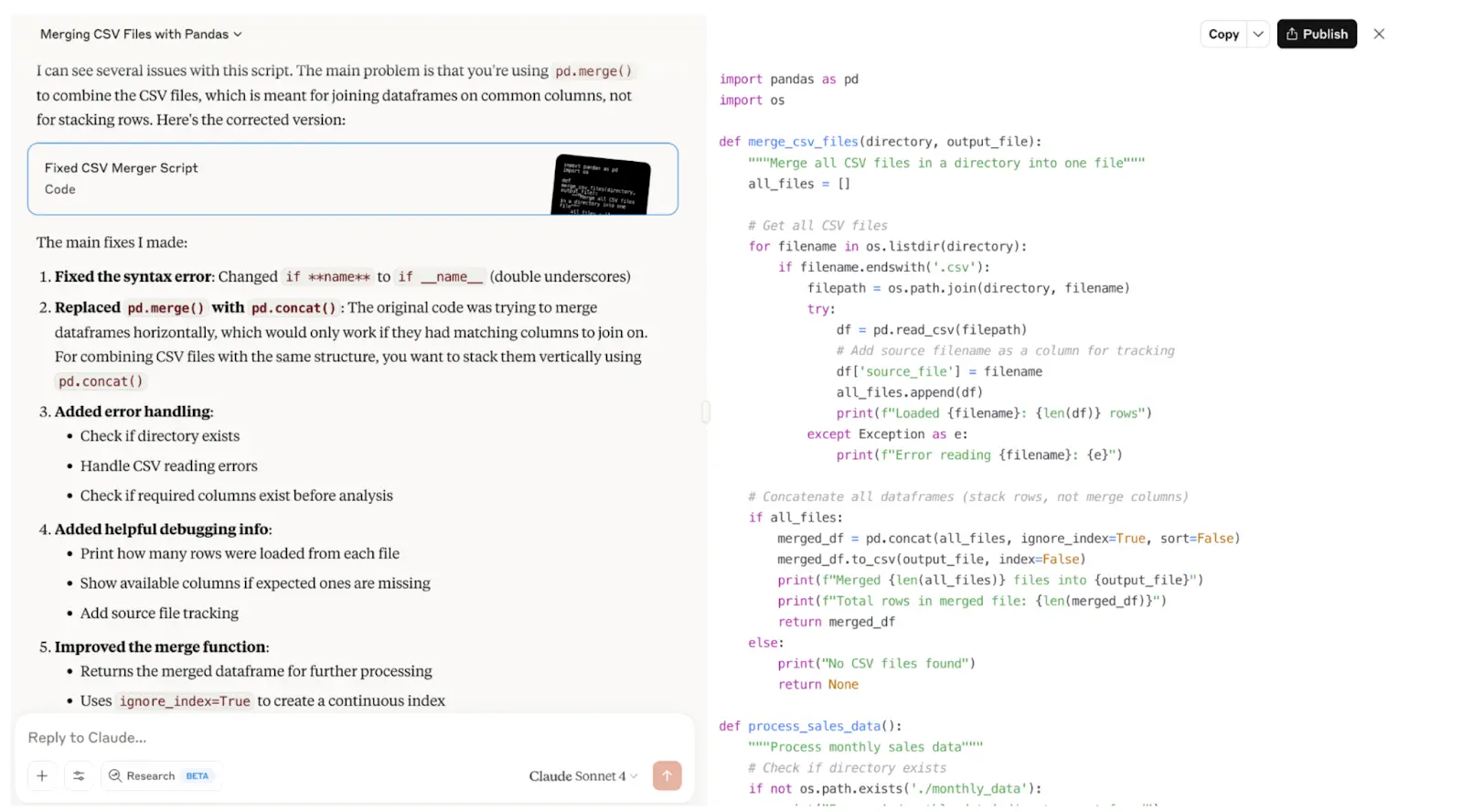
I wrote a Python script that merges CSV files. But there’s just one problem — it intentionally drops duplicate columns.
I used an intentionally vague prompt: ”This script doesn't work. Can you fix it?” Let’s see what happens.
Sonnet 4 identified the issue correctly, created an artifact, and the code ran on the first try. It also explained what was wrong, though, in a way that’s quite hard to understand.
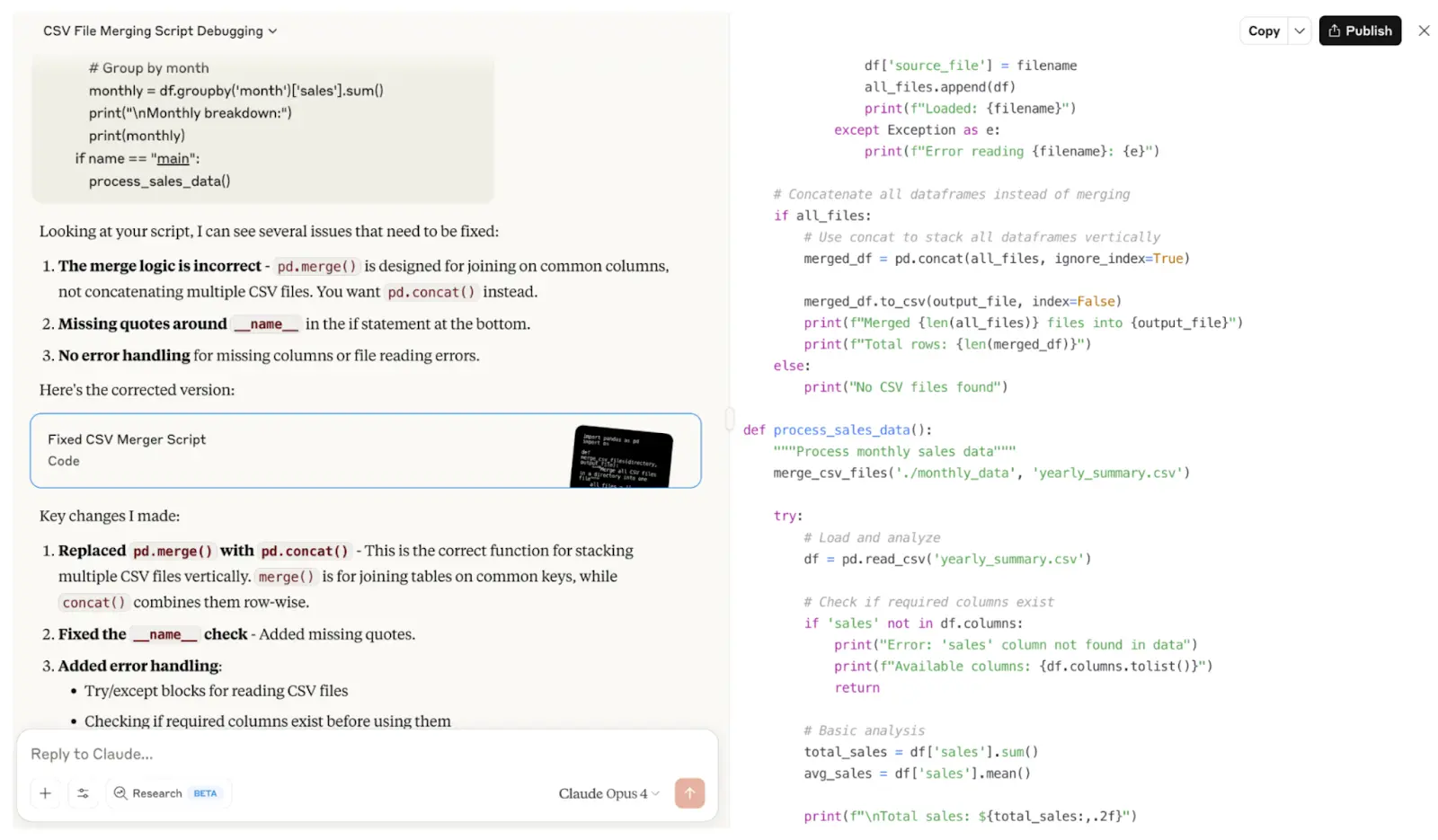
Claude Opus 4
Same buggy script to Opus 4. No surprises here — Opus had no problem finding and fixing the bug.
What’s interesting is that the resulting code is almost the same. But there’s just one important difference — and it’s not in the code.
Findings
Both models took the same approach (using pd.concat()), and implemented it similarly.
But one area where Opus outshines Sonnet, in my opinion, is the quality of the explanations. Sonnet's explanations were very technical and, frankly, almost impossible to understand. Opus, on the other hand, explained things like a good teacher would — using simple, engaging language.
Both models are effective for coding, but if you’re a beginner learning to code, you might enjoy using Opus quite a bit more than Sonnet.
Creative writing
Time to see which model is a better AI-writer. For this test, I asked:
“Create Big L-style punchline rap with Harlem references. Make it sound flowy and effortless, like freestyle.”
How did the models fare?
Claude Sonnet 4
For comparison, here’s a section from Big L’s famous hit Put it On:
“...Aiyyo, you betta flee hobbes, or get your head flown three blocks
L keep rapper's hearts pumpin' like Reeboks
And every year I gain clout and my name sprouts
Some brothers'd still be large if the crack never came out
I got the wild style, always been a foul child
My guns go poom-poom, and yo' guns go pow-pow
I'm known to have a hottie open, I keep the shottie smokin'
Front and get half the bones in your body broken”
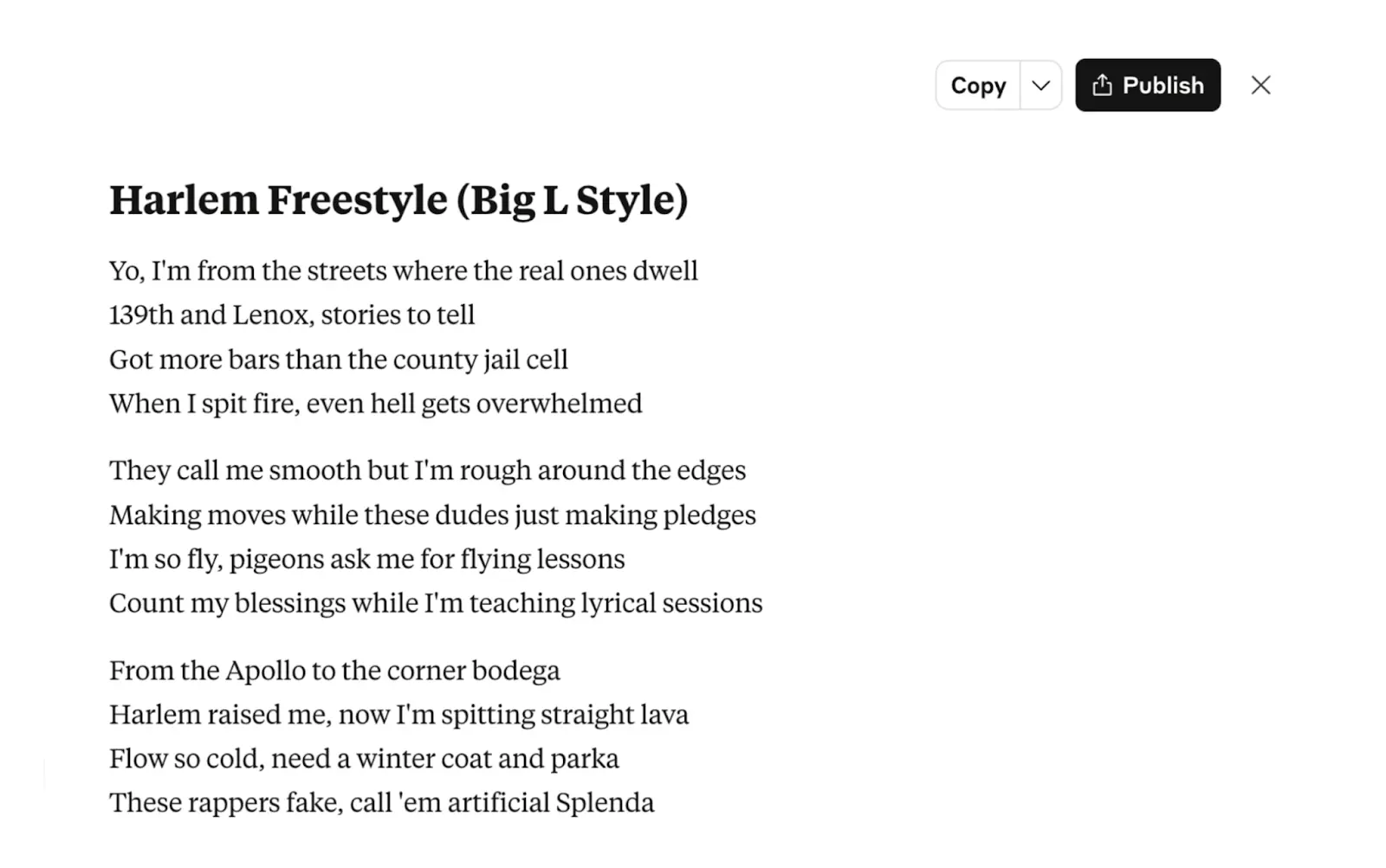
Can Sonnet 4 replicate this style? Here’s what it produced:
I don’t know about you, but I think that’s a clear miss — it overused cliches ("bars," "spit fire”) and sounds rhythmically repetitive.
Claude Opus 4
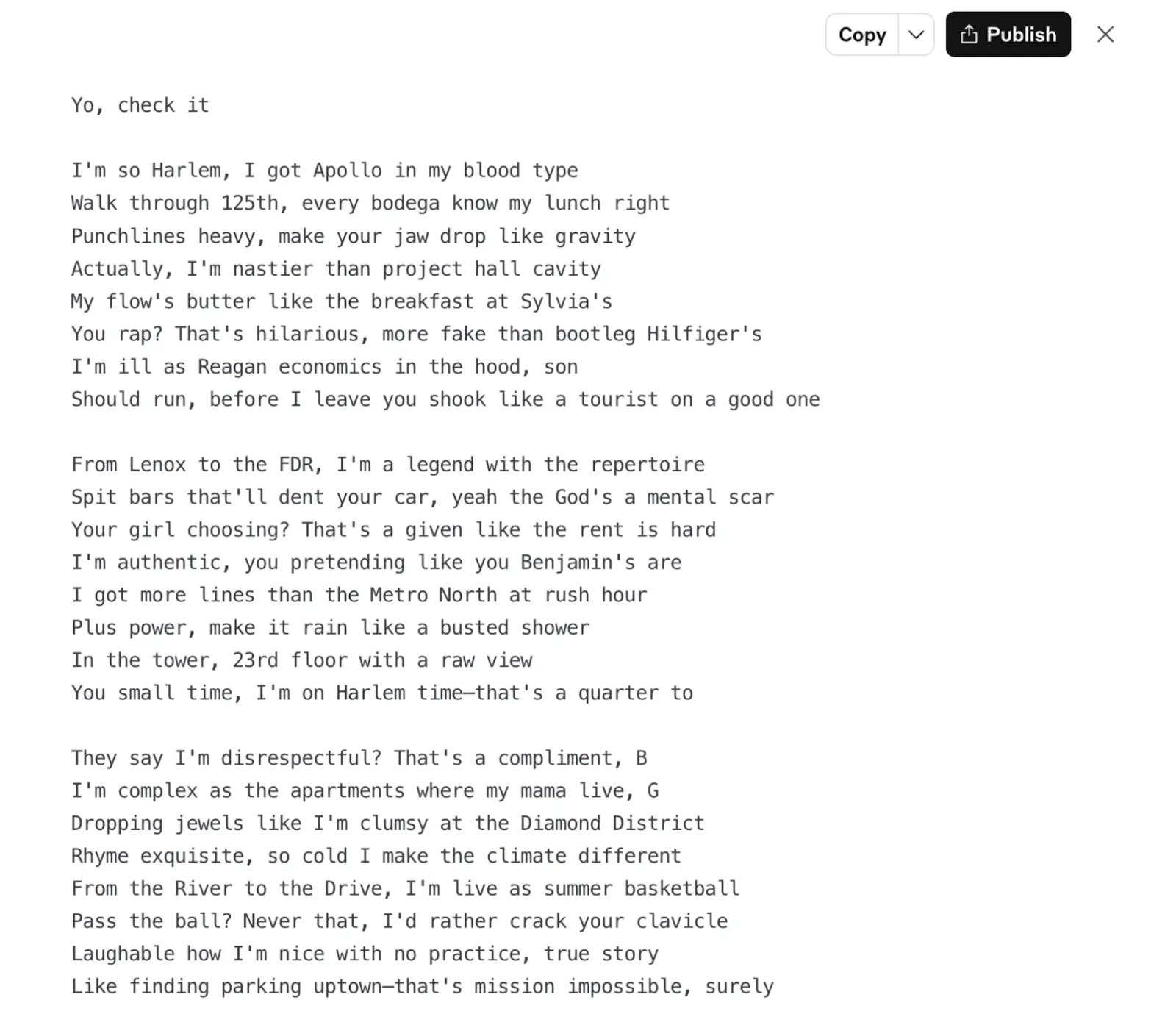
I gave Opus 4 the same prompt and, I think, the difference is quite start:
This still sounds more like Epic Rap Battles of History than Big L, but there are a lot more creative punchlines. "I'm complex as the apartments where my mama lives, G" made me chuckle, at least.
Strengths and Weaknesses Summary
Here’s how Sonnet 4 and Opus 4 did, in my opinion. Strengths:
Very fast responses (typically 2–5 seconds)
Good AI coder (Sonnet 4 is not good at explaining code)
$3/$15 per million tokens, it's cheaper than most competitors
Weaknesses:
Occasionally too verbose
The 200K context is not industry-leading, as both ChatGPT and Gemini offer models with 1M context windows.
Sonnet 4 is rather terrible at creative writing (without fine-tuning), while Opus 4 is Ok-ish.
Don’t get me wrong, Sonnet 4 and Opus 4 are a huge improvement over Claude 3.7. Mind you, for a model that’s behind Claude’s free tier, Sonnet 4 is very-very impressive.
For 90% of what people actually use AI for — drafting emails, fixing an occasional code, summarizing documents — it's a very powerful AI assistant.