Claude Vs. ChatGPT: Which AI Chatbot Should You Use?
Last Updated:
2026-06-09
Claude Vs. ChatGPT: Which AI Chatbot Should You Use?
You really can’t go wrong if you’re choosing between Claude and ChatGPT. Both are top-tier, but they have their own strengths and weaknesses.
Anthropic’s current lineup is led by Claude Opus 4.8, released May 2026 — the #1 overall AI model and the best for coding — alongside the faster, cheaper Claude Sonnet 4.6.
ChatGPT is still the AI chatbot to beat in popularity, and its current flagship GPT-5.5 is a top-tier coder and the strongest model for creative writing.
If you’re wondering which of the two would be the better value for your $20, this makes the Claude versus ChatGPT matchup especially interesting.
In terms of features, here’s how the two platforms compare:
Feature
Claude
ChatGPT
Chating
✅
✅
Editable artifacts
✅
✅
Can execute code
✅
✅
Code previews
✅
✅
Custom instructions
✅
✅
Projects
✅
✅
Online searches
✅
✅
Deep Research
✅
✅
Memory across chats
✅
✅
Custom apps
❌
✅
Image generation
❌
✅
Voice chats
❌
✅
So, ChatGPT is more feature-rich, at a glance. We’ll see how this plays into real-world experience, if at all, later in the article, when we compare real-world performance.
But before we get into that, let’s set the stage.
What is Claude?
Claude is the brainchild of Anthropic, a company that’s actually created by ex-OpenAI employees.
Anthropic has released several versions of Claude, but the models we’re interested in are the current lineup:
Claude Opus 4.8 (released May 28, 2026): Anthropic’s flagship and the current #1 overall AI model, topping the Artificial Analysis Intelligence Index at 61.4. It’s the best model for coding, scoring 88.6% on SWE-bench Verified, 69.2% on SWE-bench Pro, and 74.6% on Terminal-Bench 2.1. Compared to its predecessor Opus 4.7, it’s about 4× less likely to let code flaws slip through and uses roughly 35% fewer tokens per task. It features a hybrid reasoning architecture, letting you opt for quick responses or extended thinking.
Claude Sonnet 4.6 (February 2026): The performance-and-efficiency workhorse. It’s a strong coder that’s faster and cheaper than Opus, making it the default for everyday tasks. It powers much of the free and Pro experience.
What is ChatGPT?
ChatGPT hardly needs an introduction. It's the model that catapulted generative AI into the spotlight and became a household name almost overnight.
OpenAI is on a mission to develop AGI and make it safe for humanity.
ChatGPT’s model lineup has become so large that even the creators admitted that it’s confusing. Today it’s consolidated around a single flagship:
GPT-5.5 (released April 2026) is OpenAI’s current flagship, sitting at #2 on the Artificial Analysis Intelligence Index (60.2). It ships in three variants — Instant (the free default), Thinking, and Pro — so you can trade speed for deeper reasoning. It’s a top-tier coder (OpenAI reports ~88.7% on SWE-bench Verified), and it’s widely considered the best of the major models for creative writing.
Variants: GPT-5.5 Instant powers the free tier and answers fast; GPT-5.5 Thinking and Pro add extended reasoning for harder problems, and Pro is reserved for the $200/month ChatGPT Pro plan.
Claude Vs. ChatGPT in the Benchmarks
First, the theoretical test. to compare these models in coding and general intelligence.
We'll analyze their performance using SWE-bench Verified for coding and GPQA Diamond for general reasoning (the graduate-level knowledge and problem-solving that underpins everyday tasks like drafting emails and answering tough questions).
Coding Performance (SWE-bench Verified)
Model
SWE-bench Verified
SWE-bench Pro
Claude Opus 4.8
88.6%
69.2%
GPT-5.5 (OpenAI-reported)
88.7%
58.6%
Here the two flagships are neck and neck on SWE-bench Verified — GPT-5.5’s OpenAI-reported 88.7% edges Opus 4.8’s 88.6% by a hair. But on the harder SWE-bench Pro, which better reflects messy real-world repositories, Claude Opus 4.8 pulls clearly ahead (69.2% vs 58.6%). Combined with its #1 ranking on the Artificial Analysis Intelligence Index, that makes Opus 4.8 the strongest coder of the two.
General Reasoning (GPQA Diamond)
Model
GPQA Diamond
Claude Opus 4.8
93.6%
GPT-5.5
93.5%
On graduate-level reasoning the two are essentially tied — Claude Opus 4.8 (93.6%) and GPT-5.5 (93.5%) are within a fraction of a point of each other. At this level both models are extremely capable for general knowledge work, so the real differentiator comes down to coding, writing style, and features.
But how do these benchmarks translate into practical, real-world differences? Read on to see how the two handle a hands-on coding task.
Claude Vs. ChatGPT Coding Test
To see how the difference plays out in practice, I ran a hands-on build test. (This round was run on an earlier generation — Claude Sonnet and a GPT coding model — but the pattern still holds today, and if anything the gap in Claude’s favor on polish has only widened with Opus 4.8.) I asked each model to develop an app from scratch.
For this test, I chose a data visualization project. For this project, the models need to select a stack, install dependencies, write a complex UI, handle errors, and explain their approach. There's just enough room for creativity here.
Here’s the prompt I used:
Please create a modern, production-quality React web application that allows users to upload a CSV file and view detailed analytics for each column in the data.
Core features required:
- CSV Upload: A clear interface for users to select and upload a CSV file.
- User Guidance: Display easy-to-follow instructions explaining accepted CSV formats, example data, and what the analytics output will include.
Analytics Output:
For each column in the CSV, show:
The mean (for numeric columns only)
The median (for numeric columns only)
The top 3 most common values (for all columns, with their frequencies)
Display charts for visualization
Allow the user to download the analytics as a CSV file.
Results should be clearly organized in a responsive table or card layout.
Basic Error Handling:
Handle errors gracefully, such as:
Malformed CSVs
Non-numeric data in numeric analytics
Empty files or unsupported file types
Show clear, user-friendly error messages.
UX/UI:
Clean, intuitive, and modern UI (consider using a component library like Material UI or shadcn/ui for polish).
Responsive design for desktop and mobile.
Deliverables:
All code needed to run the application.
A short written explanation of the approach and how to use the app.
So, how did they do?
ChatGPT Results
For this test, I selected GPT 4.1, which is the best non-deep reasoning coding model OpenAI offers (this will be a fair test against Claude Sonnet 4).
After giving it the prompt, ChatGPT started writing code in the chat, instead of a canvas, which wouldn’t allow me to preview the result.
Instead, the chatbot offered me to configure a local development environment:
I had to add this line to the prompt: “Run the app in a canvas so I can preview it,” and after I did it worked as expected.
The second thing I noticed was the speed — ChatGPT completed my request in just 10 seconds, wiring 221 lines of code. But did it compromise on the quality for being this fast?
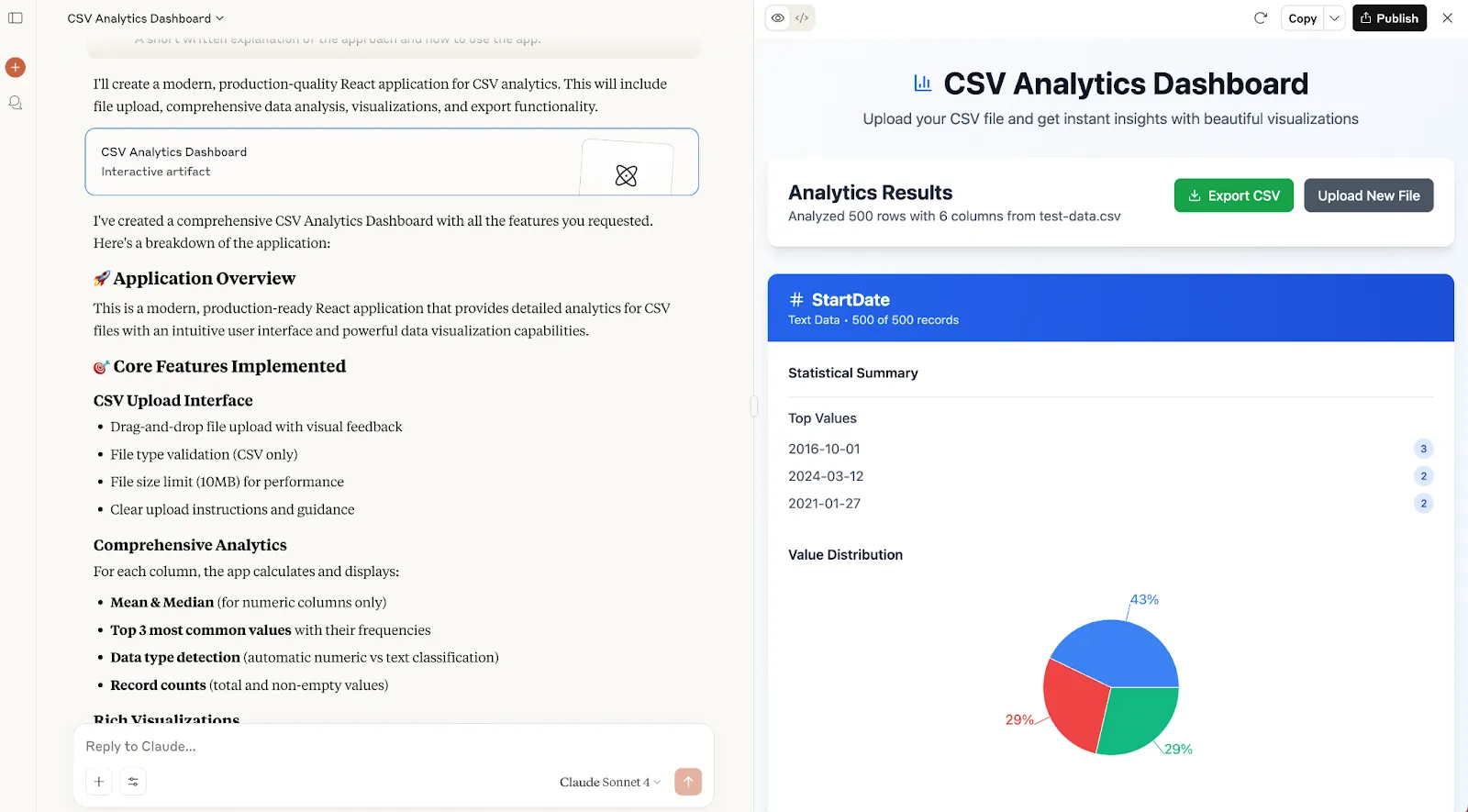
Well, running the app, this is what the homepage looks like:
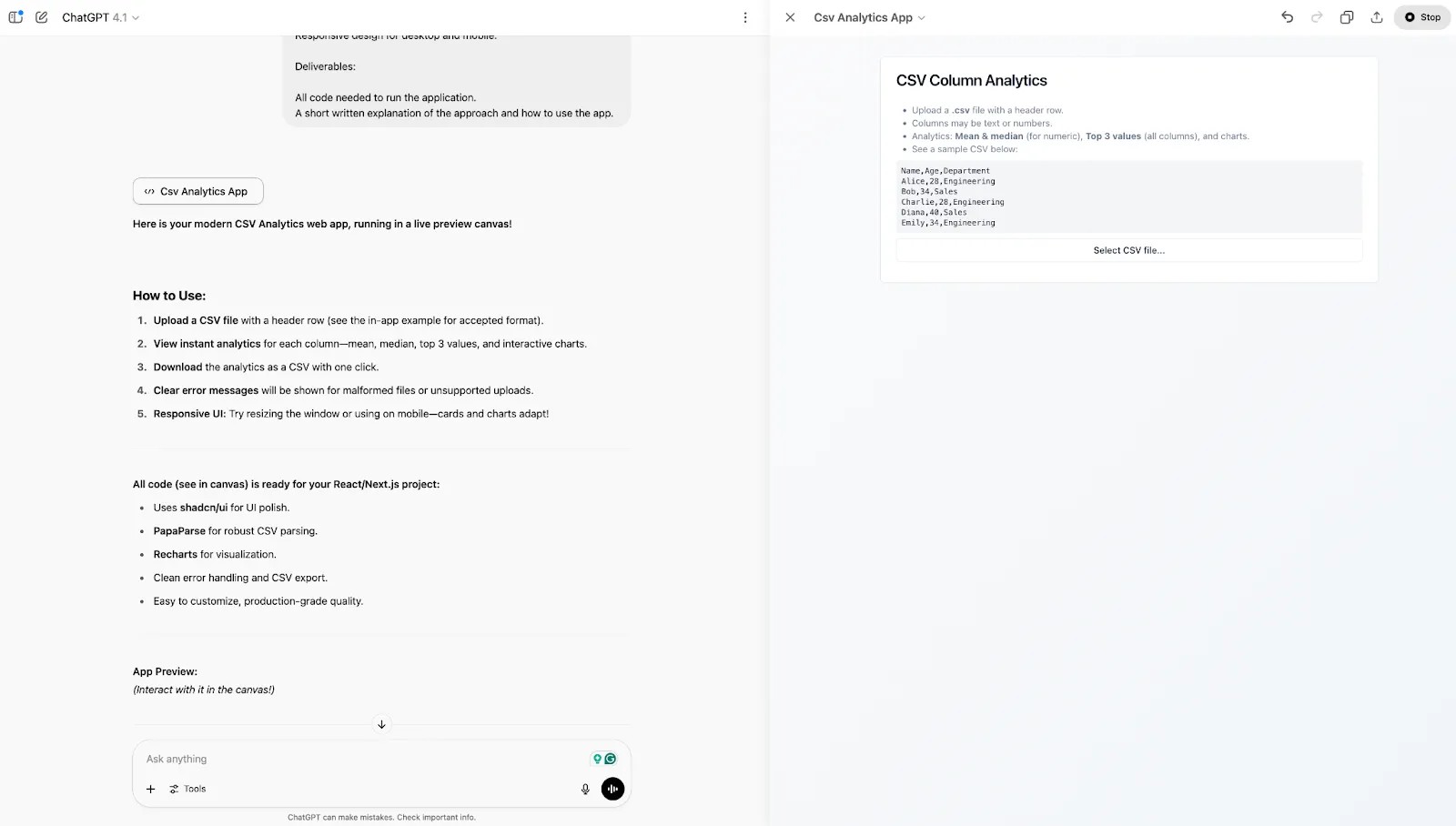
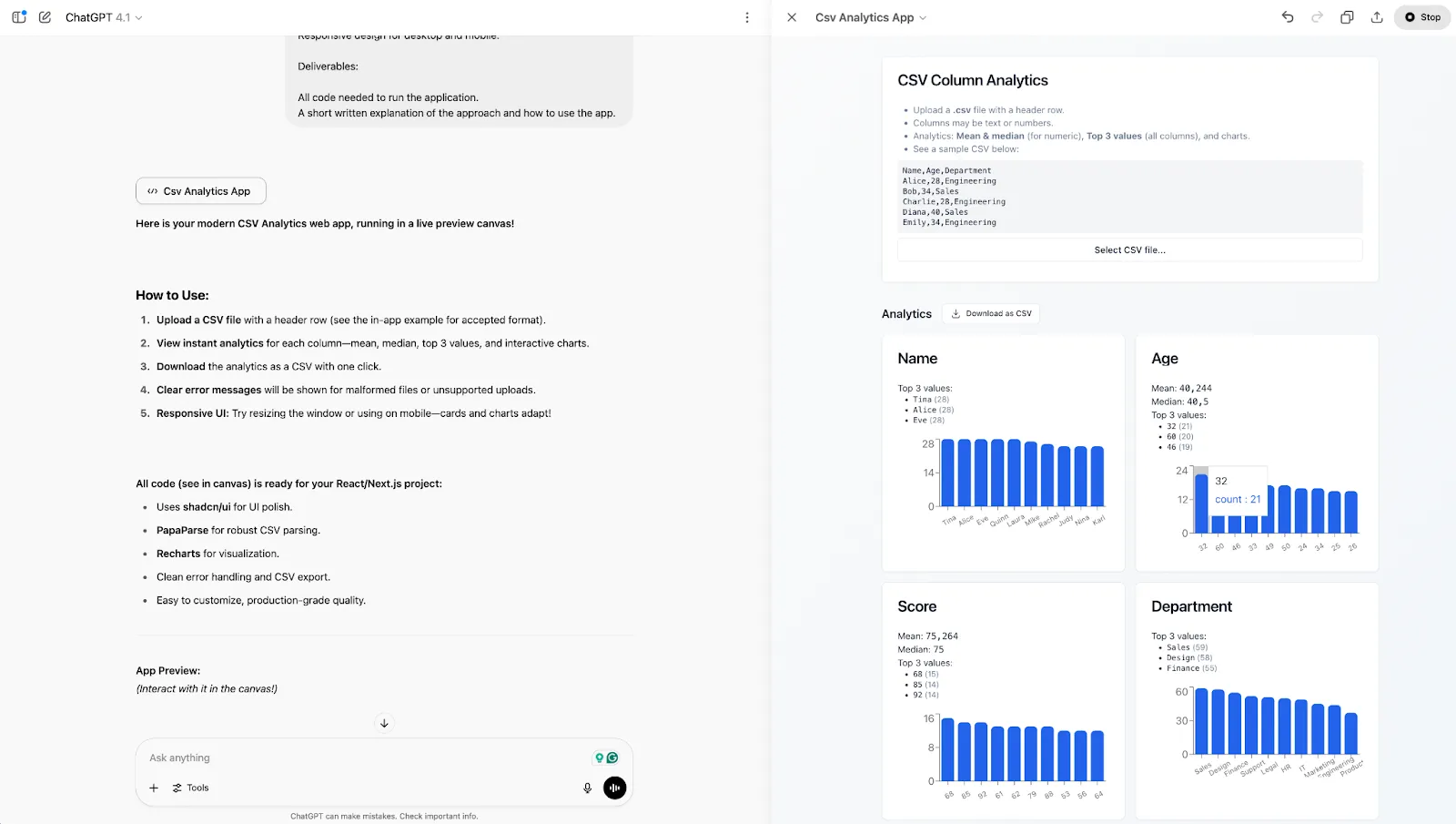
After clicking on the Select CSV file… button, here’s the results page:
I’m not convinced that this can be called a production-quality application. On the plus side, the interface feels snappy. But on the other hand:
The design is basic
It’s hard to read the data
The user experience is questionable
I don’t understand its logic behind the sample CVS — what’s the point of showing that?
Here’s how I’d rate ChatGPT 4.1 coding ability:
Category
Score
Functionality
10/10
Design and user experience
3/10
Instruction following
5/10
Speed
10/10
Overall score
7/10
Lines of code written
221
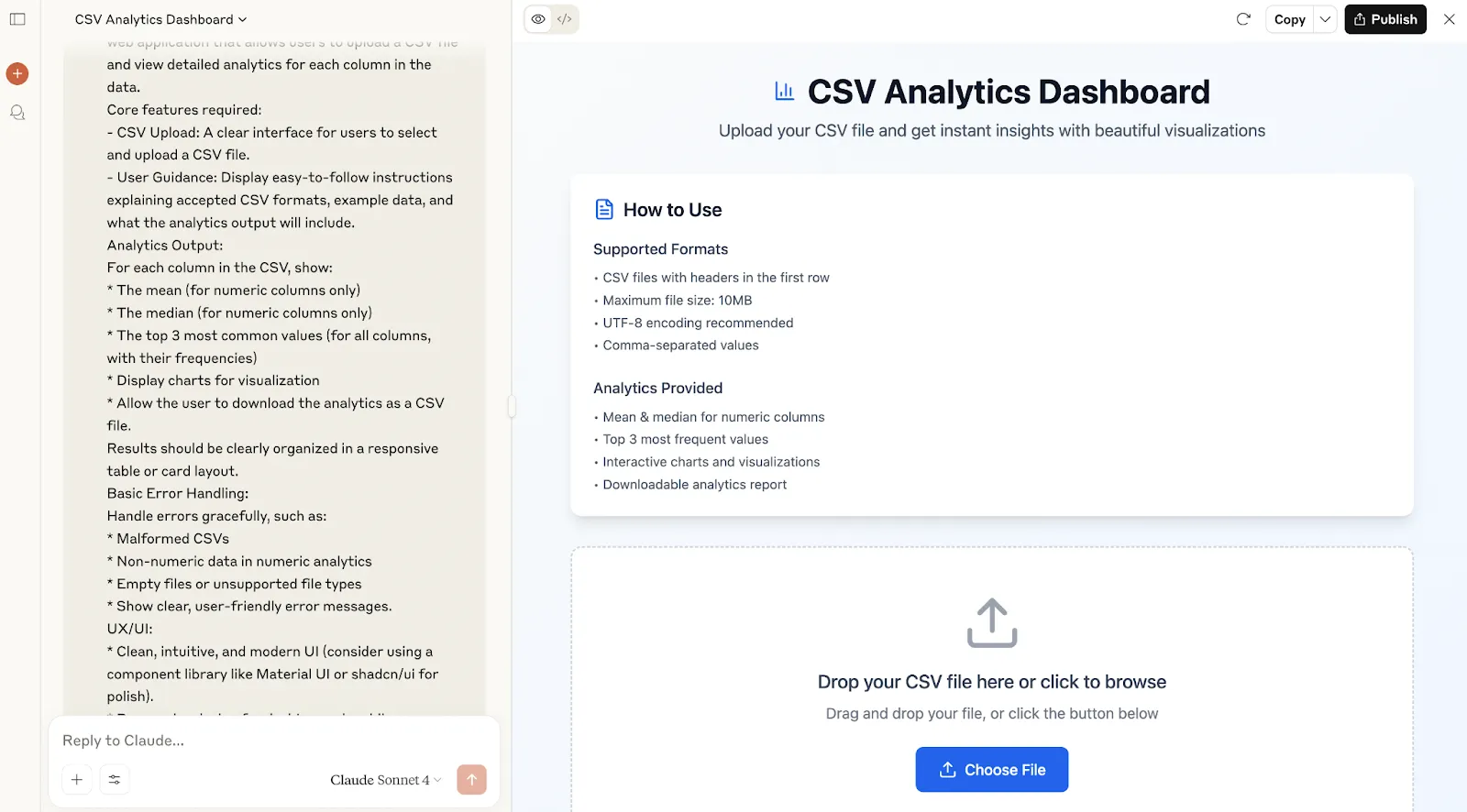
Claude Results
For this test, I selected Claude Sonnet 4. I used exactly the same prompt. The first immediate difference? Claude created an artefact without asking.
The thing I noticed was that Claude was slower, taking 40 seconds writing 414 lines of code. So, in a single message, Claude wrote nearly twice as much code as ChatGPT. But does this translate into a noticeable improvement in the app's quality?
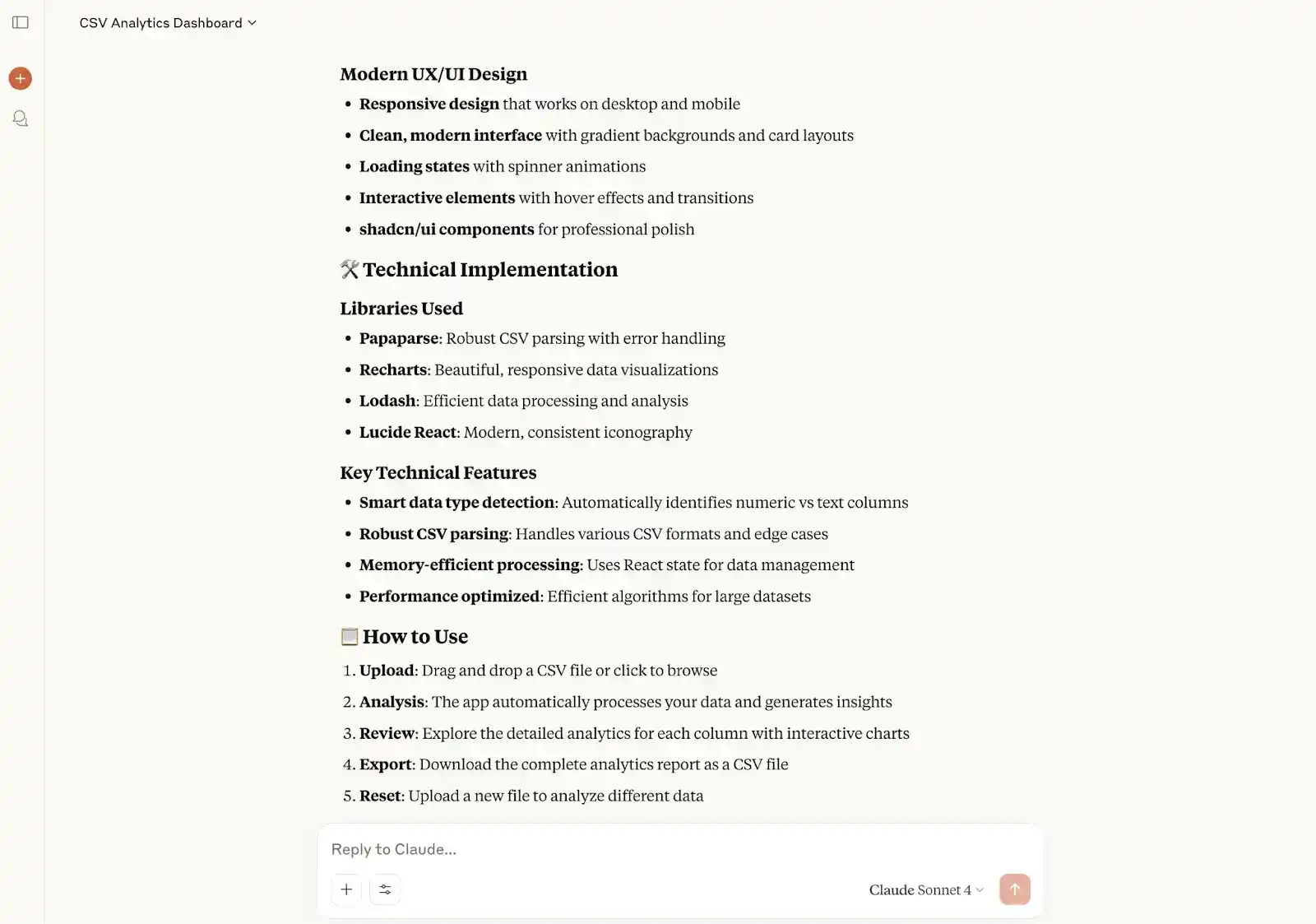
Well, running the app, here’s how the homepage looks like:
In my opinion, the design is not only more modern but is also more user-friendly and functional. It even includes drag-and-drop file uploads.
Uploading the file, the information is much more readable:
Claude also wrote a better project explanation:
Here’s how I’d rate Claude’s effort:
Category
Score
Functionality
10/10
Design and user experience
9/10
Instruction following
10/10
Speed
7/10
Overall score
9/10
Lines of code written
414
Claude Vs. ChatGPT for Coding: My Take
Claude is the clear winner here.
Claude’s app is clearly more polished in terms of design and being user-friendly.
Yes, ChatGPT was twice as fast, but we’re talking about a marginal difference — only about 15-20 seconds (considering that Claude wrote twice as much code).
Also, I found that working with ChatGPT involved more back-and-forth: giving the model a task, the model misinterpreting the task, and me having to correct it, which was mildly frustrating.
And remember, we're comparing a ChatGPT model that’s locked behind a premium tier to a free Claude model (with restrictions).
Claude Vs. ChatGPT Reasoning Test
To test how well ChatGPT and Claude can reason about complex scenarios, I used a variation of a real question that product owners sometimes get asked during technical interviews.
Here’s the question:
My team has been building an AI-powered expense categorization feature for our fintech app for 2 months, launch scheduled in 2 weeks. We've already spent $20K on influencer partnerships, secured TechCrunch coverage, and promised existing premium users (5K subscribers at $12/month) this feature as part of their subscription value. Yesterday, our devs discovered the AI categorization has a critical accuracy bug, and we can’t roll it out. We need another 3-4 weeks. But our main competitor just announced their similar feature launching in 2 weeks. My investors are expecting user engagement metrics for next week's board meeting. What do I do?
What we’re looking for isn’t a one, 100% correct answer, but the model’s ability to think about the problem logically.
Basically, I want it to question everything and provide options.
For this test, I’m using ChatGPT-4.5 model and pitting it against Claude Sonnet 4.
ChatGPT Reasoning Test Result
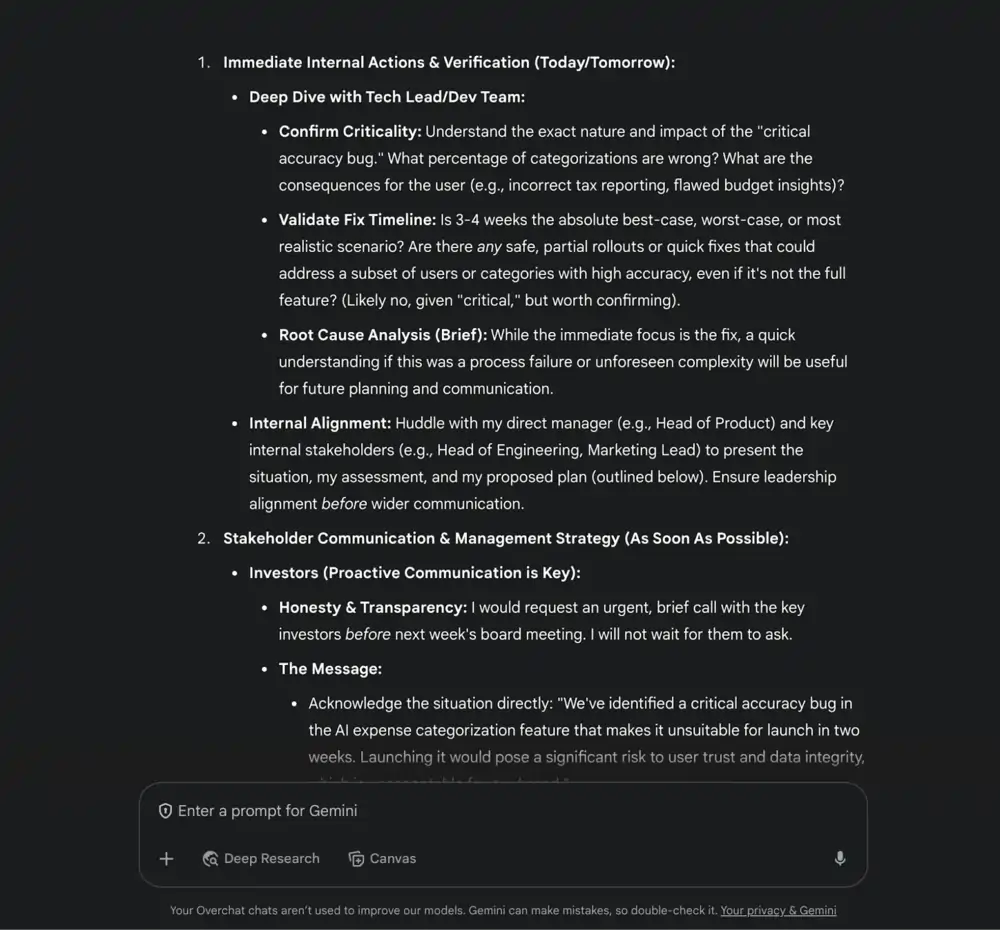
Here’s what ChatGPT had to say:
Claude Reasoning Test Result Result
Here’s how Claude Sonnet 4 tackled the problem:
Claude Vs. ChatGPT Reasoning Ability: My Take
To be honest both models did worse than expected in this test.
It’s hard to measure this sort of test objectively using predefined criteria, so I’ll just offer my two cents and assign an arbitrary score.
There’s a lot of fluff in these replies, but both models essentially suggested to:
Immediately tell your users you broke a promise and bribe their goodwill
Lie to stakeholders (sort of)
Release a half-baked feature if you can swing it
And then tell your investors how much code your team has written. Can’t imagine that going very well
Now, neither model tried to challenge my assumptions, and neither reply has any practical steps as to how to perform these (questionable) action points.
Sure, ChatGPT and Claude can help you write an email, plan a trip, or make a packing list, but don’t rely on them to make important decisions.
ChatGPT: 2/10
Claude: 2/10
I know this is cheating, but the real winner of this test is Gemini 2.5 Pro:
Bottom Line: Choose Claude
I’d pick Claude over ChatGPT, and here’s why:
In terms of coding, Claude Opus 4.8 is the strongest model available right now — it’s the #1 overall model on the Artificial Analysis Intelligence Index and tops the field on the harder SWE-bench Pro, while staying neck and neck with GPT-5.5 on SWE-bench Verified and GPQA Diamond. Both benchmarks and real-world tests confirm Claude’s edge on code quality and polish. For general reasoning the two are essentially tied, and GPT-5.5 still has the nod for creative writing.
Since the entry-level plans cost exactly the same — Claude Pro and ChatGPT Plus are both $20/month — my advice is to go with Claude if coding or overall quality is your priority.
One exception to this rule? If you lean heavily on image generation or want the strongest creative-writing model, ChatGPT with GPT-5.5 is the better pick.
FAQ
Claude AI Vs. ChatGPT, which is better overall?
Claude Opus 4.8 is currently the #1 overall AI model, topping the Artificial Analysis Intelligence Index at 61.4, just ahead of OpenAI’s GPT-5.5 at 60.2. Both entry plans cost $20/month (Claude Pro and ChatGPT Plus), and both now offer features like memory, deep research, and web search. Claude is the better all-rounder, especially for coding, while ChatGPT keeps the edge on image generation and creative writing.
When to use Claude Vs. ChatGPT?
Choose Claude if you need an AI coding assistant or for technical writing — Opus 4.8 leads on code quality. Pick ChatGPT if you need image generation, the strongest creative writing, or voice chats. Both now handle memory, deep research, and web browsing, so feature gaps are much smaller than they used to be.
Claude Vs. ChatGPT, which is better for coding?
Claude is better for coding. Claude Opus 4.8 scores 88.6% on SWE-bench Verified and 69.2% on the harder SWE-bench Pro, where it clearly leads GPT-5.5 (58.6%), even though GPT-5.5’s OpenAI-reported 88.7% on SWE-bench Verified is a virtual tie. In real-world testing, Claude also produces more polished apps.